

CVPR 2024 | 借助神经结构光,浙大实现动态三维现象的实时采集重建
- 创业科技
- 2024-05-06
- 9
- 更新:2024-05-06 18:01:17

AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com。
对于烟雾等动态三维物理现象的高效高质量采集重建是相关科学研究中的重要问题,在空气动力学设计验证,气象三维观测等领域有着广泛的应用前景。通过采集重建随时间变化的三维密场度序列,可以帮助科学家更好地理解与验证真实世界中的各类复杂物理现象。

图 1:观测动态三维物理现象对科学研究至关重要。图为全球更大风洞 NFAC 对商用卡车实体开展空气动力学实验 [1]。
然而,从真实世界中快速获取并高质量重建出动态三维密度场相当困难。首先,三维信息难以通过常见的二维图像传感器(如相机)直接测量。此外,高速变化的动态现象对物理采集能力提出了很高的要求:需要在很短的时间内完成对单个三维密度场的完整采样,否则三维密度场本身将发生变化。这里的根本挑战是如何解决测量样本和动态三维密度场重建结果之间的信息量差距。
当前主流研究工作通过先验知识弥补测量样本信息量不足,计算代价高,且当先验条件不满足时重建质量不佳。与主流研究思路不同,浙江大学计算机辅助设计与图形系统全国重点实验室的研究团队认为解决难题的关键在于提高单位测量样本的信息量。
该研究团队不仅利用 AI 优化重建算法,还通过 AI 帮助设计物理采集方式,实现同一目标驱动的全自动软硬件联合优化,从本质上提高单位测量样本关于目标对象的信息量。通过对真实世界中的物理光学现象进行仿真,让人工智能自己决定如何投射结构光,如何采集对应的图像,以及如何从采样样本中重建出动态三维密度场。最终,研究团队仅使用包含单投影仪和少量相机(1 或者 3 台)的轻量级硬件原型,把建模单个三维密度场(空间分辨率 128x128x128)的结构光图案数量降到 6 张,实现每秒 40 个三维密度场的高效采集。
值得一提的是,团队在重建算法中创新性地提出轻量级一维解码器,将局部入射光作为解码器输入的一部分,在不同相机所拍摄的不同像素下共用了解码器参数,大幅降低 *** 的复杂程度,提高计算速度。为融合不同相机的解码结果,又设计结构简单的 3D U-Net 聚合 *** 。最终重建单个三维密度场仅需 9.2ms,相对于 SOTA 研究工作 [2,3],重建速度提升 2-3 个数量级,实现三维密度场的实时高质量重建。相关研究论文《Real-time Acquisition and Reconstruction of Dynamic Volumes with Neural Structured Illumination》已被计算机视觉顶级国际学术会议 CVPR 2024 接收。

论文链接:https://svbrdf.github.io/publications/realtimedynamic/realtimedynamic.pdf
研究主页:https://svbrdf.github.io/publications/realtimedynamic/project.html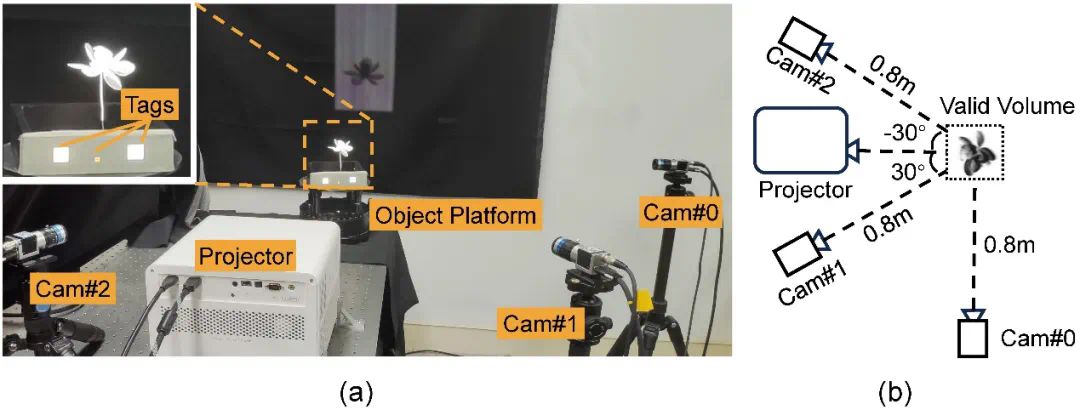
图 3:采集硬件原型。(a)硬件原型实拍图,其中载物台上的三个白色标记(tags)用于同步相机和投影仪。(b)相机、投影仪与拍摄对象之间几何关系的示意图(顶部视角)。
软件处理
研发团队设计由编码器、解码器和聚合模块组成的深度神经 *** 。其编码器中的权重直接对应采集期间的结构光照亮度分布。解码器以单像素上测量样本为输入,预测一维密度分布并插值到三维密度场。聚合模块将每个相机所对应解码器预测的多个三维密度场组合成最终的结果。通过使用可训练结构光以及和轻量级一维解码器,本研究更容易学习到结构光图案,二维拍摄照片和三维密度场三者之间的本质联系,不容易过拟合到训练数据中。以下图 4 展示整体流水线,图 5 展示相关 *** 结构。
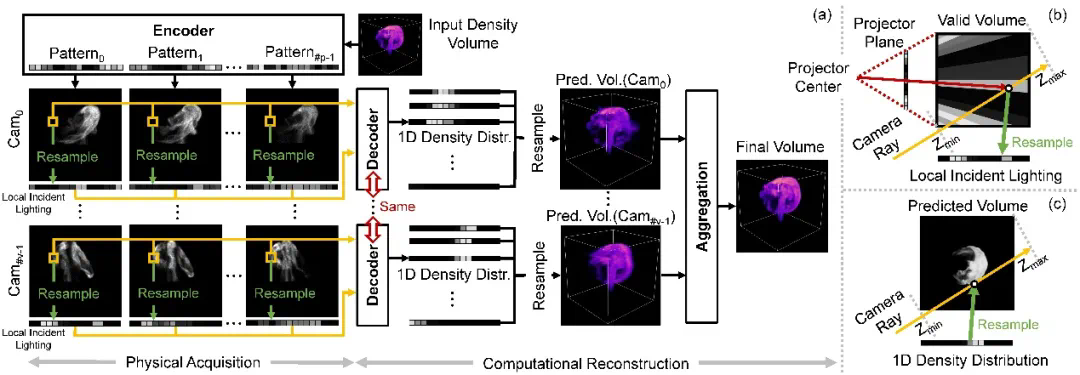
图 4:整体采集重建流水线 (a),以及从结构光图案到一维局部入射光 (b) 和从预测的一维密度分布回到三维密度场 (c) 的重采样过程。该研究从仿真 / 真实的三维密度场开始,首先将预先优化的结构光图案(即编码器中的权重)投影到该密度场。对于每个相机视图中的每个有效像素,将其所有测量值以及重采样的局部入射光送给解码器,以预测对应相机光线上的一维密度分布。然后收集一台相机的所有密度分布并将其重采样到单个三维密度场中。在多相机情况下,该研究融合每台相机的预测密度场以获得最终结果。
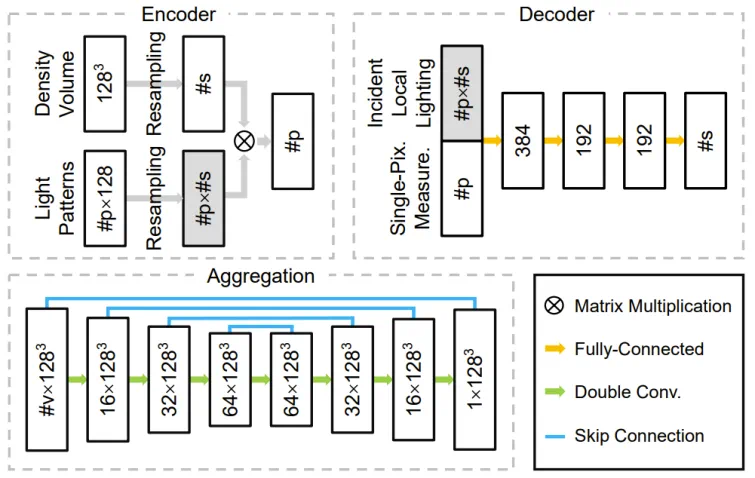
图 5: *** 3 个主要部件的架构:编码器、解码器和聚合模块。
结果展示
图 6 展示本 *** 对四个不同动态场景的部分重建结果。为生成动态水雾,研究人员将干冰添加到装有液态水的瓶子中制造水雾,并通过阀门控制流量,并使用橡胶管将其进一步引导至采集装置。
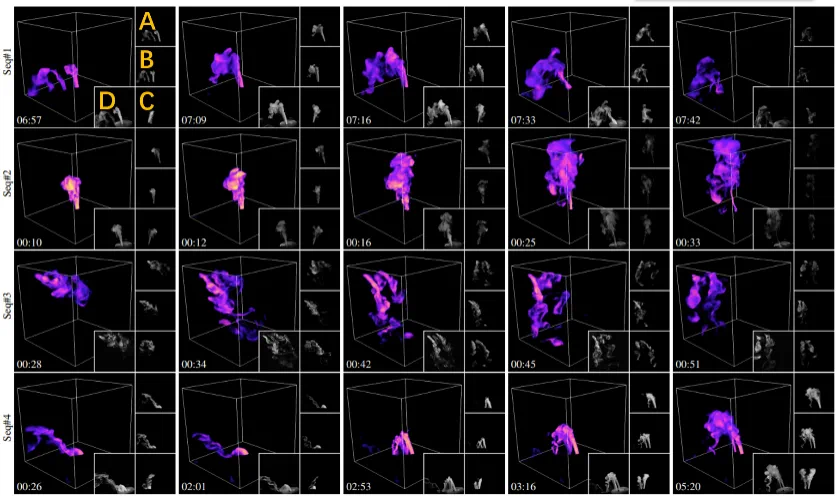
图 6:不同动态场景的重建结果。每一行是某水雾序列中选取部分重建帧的可视化结果,从上到下场景水雾源个数分别为:1,1,3 和 2。如左上方的橙色标注所示,A,B,C 分别对应三个输入相机所采集的图像,D 为和重建结果渲染视角类似的实拍参考图像。时间戳在左下角展示。详细的动态重建结果请参见论文视频。
为了验证本研究的正确性和质量,研究团队在真实静态物体上把本 *** 和相关 SOTA *** 进行对比(如图 7 所示)。图 7 也同时对不同相机数量下的重建质量进行对比。所有重建结果在相同的未采集过的新视角下绘制,并由三个评价指标进行定量评估。由图 7 可知,得益于对采集效率的优化,本 *** 的重建质量优于 SOTA *** 。

图 7:不同技术在真实静态物体上的比较。从左到右是光学层切 *** [4],本 *** (三相机),本 *** (双相机),本 *** (单相机),单相机下使用手工设计的结构光 [5],SOTA 的 PINF [3] 和 GlobalTrans [2] *** 的重建结果可视化。以光学层切结果为基准,对于所有其他结果,其定量误差列在相应图像的右下角,用三种指标 SSIM/PSNR/RMSE (0.01) 来评估。所有重建密度场均使用非输入视图进行渲染,#v 表示采集的视图数量,#p 表示所用结构光图案的数量。
研究团队也在动态仿真数据上对不同 *** 的重建质量进行定量对比。图 8 展示仿真烟雾序列的重建质量对比。详细的逐帧重建结果请参见论文视频。

图 8:仿真烟雾序列上不同 *** 的比较。从左到右依次为真实值,本 *** ,PINF [3] 和 GlobalTrans [2] 重建结果。输入视图和新视图的渲染结果分别显示在之一行和第二行中。定量误差 SSIM/PSNR/RMSE (0.01) 展示在相应图像的右下角。整个重建序列的误差平均值请参考论文补充材料。另外,整个序列的动态重建结果请参见论文视频。
未来展望
研究团队计划在更先进的采集设备(如光场投影仪 [6])上应用本 *** 开展动态采集重建。团队也期望通过采集更丰富的光学信息(如偏振状态),从而进一步减少采集所需的结构光图案数量和相机数量。除此之外,将本 *** 与神经表达(如 NeRF)结合也是团队感兴趣的未来发展方向之一。最后,让 AI 更主动地参与对物理采集与计算重建的设计,不局限于后期软件处理,这可能能为进一步提升物理感知能力提供新的思路,最终实现不同复杂物理现象的高效高质量建模。
参考资料:
[1]. Inside the Worlds Largest Wind Tunnel https://youtu.be/ubyxYHFv2qw?si=KK994cXtARP3Atwn
[2]. Erik Franz, Barbara Solenthaler, and Nils Thuerey. Global transport for fluid reconstruction with learned selfsupervision. In CVPR, pages 16321642, 2021.
[3]. Mengyu Chu, Lingjie Liu, Quan Zheng, Erik Franz, HansPeter Seidel, Christian Theobalt, and Rhaleb Zayer. Physics informed neural fields for *** oke reconstruction with sparse data. ACM Transactions on Graphics, 41 (4):114, 2022.
[4]. Tim Hawkins, Per Einarsson, and Paul Debevec. Acquisition of time-varying participating media. ACM Transactions on Graphics, 24 (3):812815, 2005.
[5]. Jinwei Gu, Shree K. Nayar, Eitan Grinspun, Peter N. Belhumeur,and Ravi Ramamoorthi. Compressive structured light for recovering inhomogeneous participating media.IEEE Transactions on Pattern Analysis and Machine Intelligence,35 (3):11, 2013.
[6]. Xianmin Xu, Yuxin Lin, Haoyang Zhou, Chong Zeng, Yaxin Yu, Kun Zhou, and Hongzhi Wu. A unified spatial-angular structured light for single-view acquisition of shape and reflectance. In CVPR, pages 206215, 2023.
本文由 @小畔畔 于2024-05-06发布在 畔畔网,如有疑问,请联系我们。
上一篇:dll怎么导入act