

CVPR 2024 | 文本一键转3D数字人骨骼动画,阿尔伯塔大学提出MoMask框架
- 创业科技
- 2024-04-29
- 9
- 更新:2024-04-29 20:01:04

AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com。
想象一下,你仅需要输入一段简单的文本描述,就可以生成对应的 3D 数字人动画的骨骼动作。而以往,这通常需要昂贵的动作捕捉设备或是专业的动画师逐帧绘制。这些骨骼动作可以进一步的用于游戏开发,影视 *** ,或者虚拟现实应用。来自阿尔伯塔大学的研究团队提出的新一代 Text2Motion 框架,MoMask,正在让这一切变得可能。
论文题目:MoMask: Generative Masked Modeling of 3D Human Motions
论文链接:https://arxiv.org/abs/2312.00063
代码链接:https://github.com/EricGuo5513/momask-codes
Huggingface Space 链接:https://huggingface.co/spaces/MeYourHint/MoMask
MoMask 模型介绍
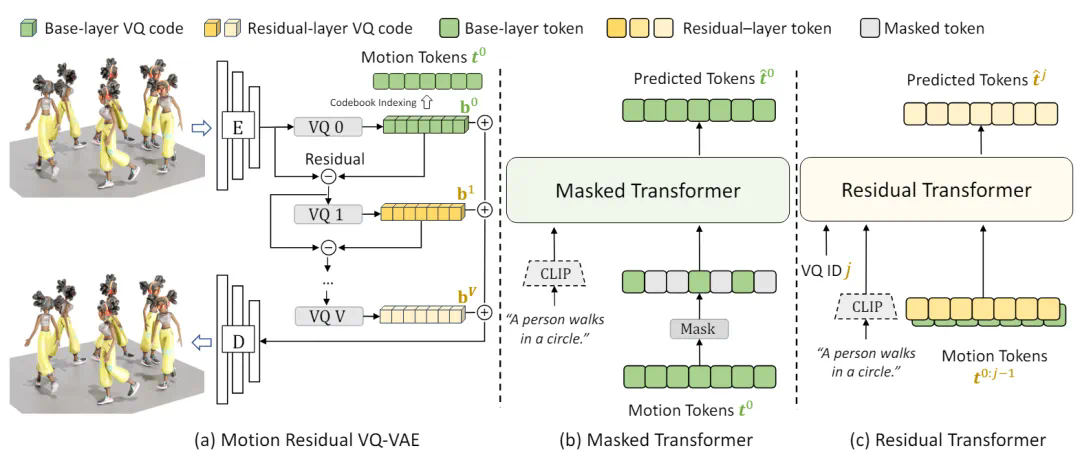
图 2:MoMask 框架结构与训练流程
MoMask 框架主要包含三个关键的神经 *** 模块:
残差量化模型 (Residual VQ-VAE),将人体动作转换为多层离散的动作标记(Token)。基层(即之一层)的动作标记包含了动作的基本信息,而残差层则对应更细粒度的动作信息。
Masked Transformer:对基层的动作标记进行建模,采用随机比例的随机掩码,并根据文本信息预测被掩码的动作标记,用于生成基层动作标记。
Residual Transformer:对残差层的动作标记进行建模,根据前 j 层的动作标记预测第 j 层的动作标记,以此来建模残差层的动作序列。
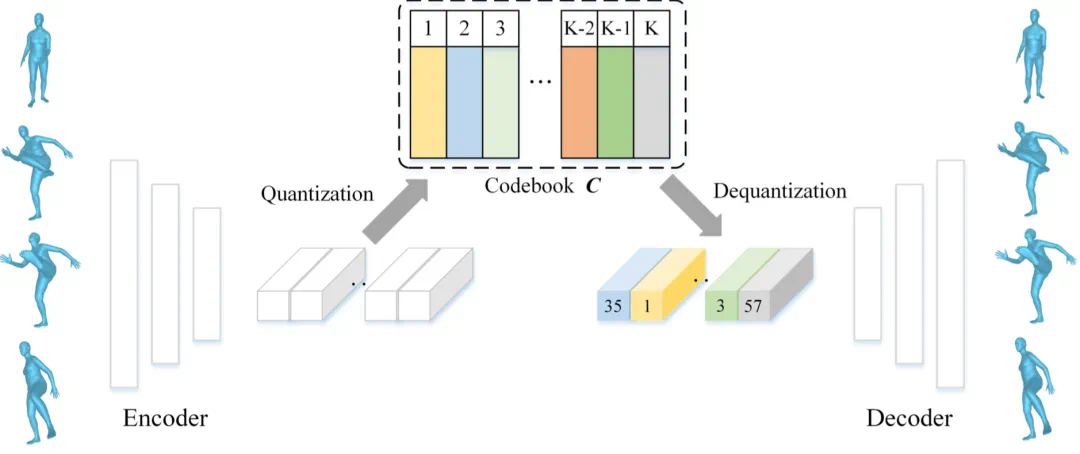
图 3: T2M-GPT 的动作离散化模型 (VQ-VAE)
动作序列离散化。MoMask 采用基于离散表达的生成式框架,首先将连续的动作表达进行离散化。如图 3,传统的 VQ-VAE 在量化(Quantization)过程中存在信息损失问题,因为它将每个隐向量替换为码书(Codebook)中最相近的码向量,这两个向量之间的差异导致了信息的丢失。为了解决这个问题,MoMask 采用了多层量化的 *** (图 2.a),逐层对隐向量和码向量之间的残差进一步量化,从而提高了隐向量的估计精度。随着层数加深,每一层所建模的信息量(即残差)也逐步减少。训练时,为了尽可能增加每一个量化层的容量,我们随机丢弃掉末尾的若干个残差层。最终,动作序列被转化为多层的离散动作标记,其中基层标记包含了动作的主要内容,而残差层则用于填补动作的细节。接下来,MoMask 使用 Masked Transformer 生成基层动作标记,并使用 Residual Transformer 逐层预测残差层的动作标记。
生成式掩码建模。如图 2.b,文本描述首先通过 CLIP 编码成语义向量,同时基层的动作标记序列被随机掩码。然后,这些掩码的动作标记序列和 CLIP 文本向量一起输入到 Transformer 中进行训练,其目标是准确预测被掩码掉的动作标记。与以往基于掩码的预训练模型不同的是,这里掩码标记的比例是随机的,并且可以在 0 到 1 的区间取值,这意味着掩码的程度也是随机的。最坏情况下,所有标记都被掩码,而更好情况下,所有标记都被保留。
残差层标记预测。由于残差层包含了更细粒度的动作信息,因此根据前面 j 1 层的动作标记内容,可以基本确定第 j 层的动作标记。在训练时,随机选择一个残差层 j 进行预测,将已知的前 j 层的动作标记、CLIP 文本向量以及第 j 层的编码输入到 Transformer 中,使用交叉熵损失函数来优化模型。
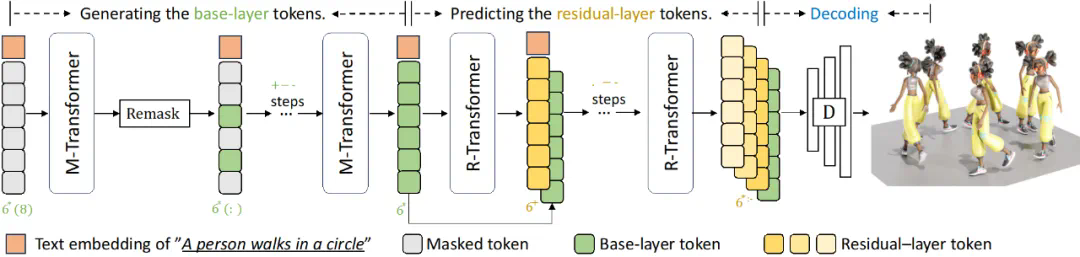
图 4: MoMask 推断流程
生成过程。图 4 描述了 MoMask 框架中的生成过程。从基层的动作标记序列开始,所有的动作标记都被掩码,然后通过 Masked Transformer 进行预测,得到完整的标记序列。接着,仅置信度更高的一部分标记被保留,剩下的标记将被重新掩码(Remask),并重新预测。通过一个预设的调度函数 (Schedule function),在经过一定次数的掩码与预测后,得到最终的基层动作标记序列。然后,Residual Transformer 根据基层的标记序列,逐层地预测残差层的标记序列。最终,所有标记序列被输入到 RVQ-VAE 的解码器中,并解码获得对应的动作序列。因此,无论动作序列的长度为多少,MoMask 只需要固定步数去生成该序列。通常情况下,MoMask 仅需要进行不超过 20 步的迭代,包括基础与残差层的生成。
实验结果
图 5 展示了 Masked Transformer 推断步数对生成动作的整体质量影响,其中 FID 和 MM-Dist 分别指示了动作生成质量以及动作与文本内容的匹配程度,值越低代表性能越好。从图中可以看出,仅需要进行 10 步推断,生成质量就可以收敛到更优水平。
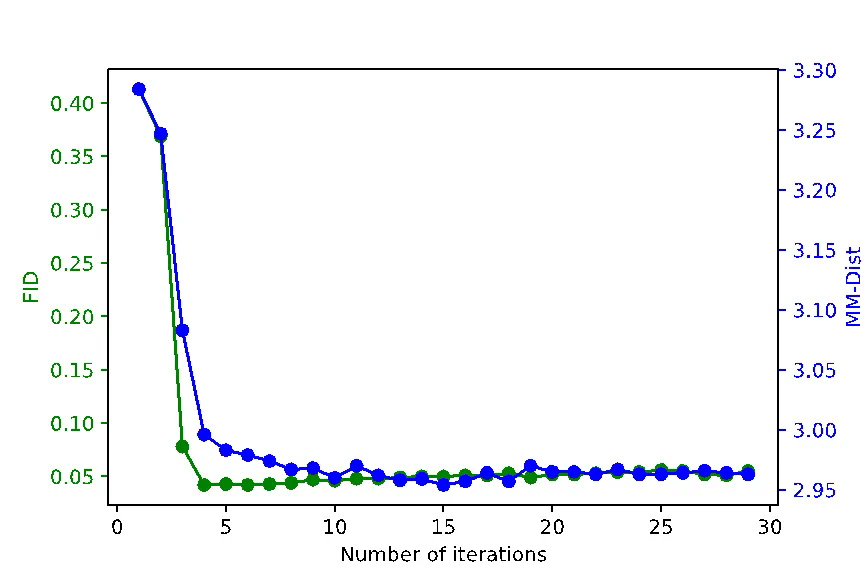
图 5: 推断步数对生成质量影响
应用:动作时序补齐
MoMask 还可用于动作序列的时序补齐,即根据文本对动作序列指定的区间进行编辑或修改。在视频 3 中,展示了基于 MoMask 对动作序列的前缀、中间部分和后缀,根据给定的文本进行内容补齐。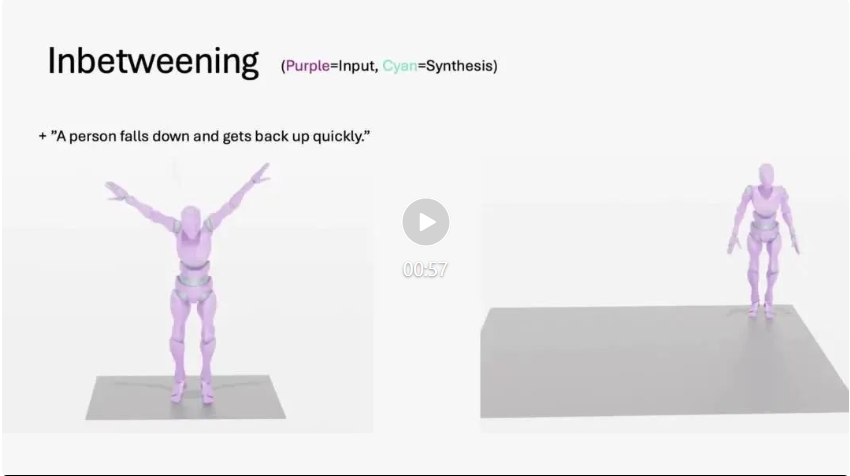 视频 3: 基于 MoMask 的动作时序补齐
视频 3: 基于 MoMask 的动作时序补齐
本文由 @小畔畔 于2024-04-29发布在 畔畔网,如有疑问,请联系我们。
上一篇:零基础的义乌老板娘秒变外语达人