

CVPR 2024 | 跳舞时飞扬的裙摆,AI也能高度还原了,南洋理工提出动态人体渲染新范式
- 创业科技
- 2024-04-22
- 5
- 更新:2024-04-22 16:00:43

AIxiv专栏是本站发布学术、技术内容的栏目。过去数年,本站AIxiv专栏接收报道了2000多篇内容,覆盖全球各大高校与企业的顶级实验室,有效促进了学术交流与传播。如果您有优秀的工作想要分享,欢迎投稿或者联系报道。投稿邮箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com。
在日常活动中,人的运动经常引起衣服的附属运动 (secondary motion of clothes) 并因此产生不同的衣服褶皱,而这需要对人体及衣服的几何、运动(人体姿态及速度动力学等)及外观同时进行动态建模。由于此过程涉及复杂的人与衣服的非刚体物理交互,导致传统三维表征往往难以应对。
近年从视频序列中学习动态数字人渲染已取得了极大的进展,现有 *** 往往把渲染视为从人体姿态到图像的神经映射,采用 「运动编码器;运动特征;外观解码器」的范式。而该范式基于图像损失做监督,过于关注每一帧图像重建而缺少对运动连续性的建模,因此对复杂运动如 「人体运动及衣服附属运动」难以有效建模。
为解决这一问题,来自新加坡南洋理工大学 S-Lab 团队提出运动;外观联合学习的动态人体重建新范式,并提出了基于人体表面的三平面运动表征 (surface-based triplane),把运动物理建模和外观建模统一在一个框架中,为提升动态人体渲染质量开辟了新的思路。该新范式可有效对衣服附属运动建模,并可用于从快速运动的视频(如跳舞)中学习动态人体重建,以及渲染运动相关的阴影。在渲染效率上比三维体素渲染 *** 快 9 倍,LPIPS 图像质量提高约 19 个百分点。

论文标题:SurMo: Surface-based 4D Motion Modeling for Dynamic Human Rendering
论文地址:https://arxiv.org/pdf/2404.01225.pdf
项目主页:https://taohuumd.github.io/projects/SurMo
Github 链接:https://github.com/TaoHuUMD/SurMo
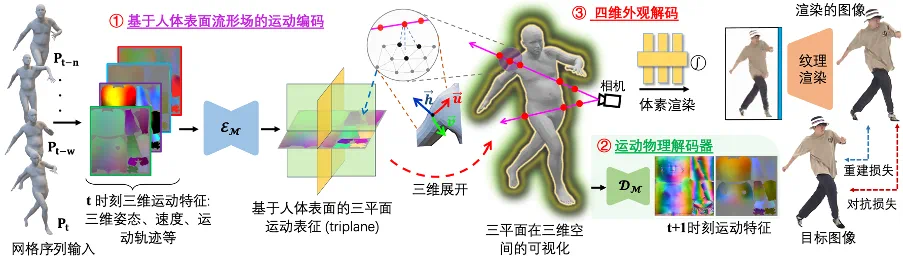
针对已有范式「运动编码器;运动特征;外观解码器」只关注于外观重建而忽略运动连续性建模的缺点,提出了新范式 SurMo:「①运动编码器;运动特征;;②运动解码器、③外观解码器」。如上图所示,该范式分为三个阶段:
区别于已有 *** 在稀疏三维空间对运动建模,SurMo 提出基于人体表面流形场(或紧凑的二维纹理 UV 空间)的四维(XYZ-T)运动建模,并通过定义在人体表面的三平面(surface-based triplane)来表征运动。
提出运动物理解码器去根据当前运动特征(如三维姿态、速度、运动轨迹等)预测下一帧运动状态,如运动的空间偏导;表面法向量和时间偏导;速度,以此对运动特征做连续性建模。
四维外观解码,对运动特征在时序上解码以此渲染三维自由视点视频,主要通过混合体素;纹理神经渲染方式实现 (Hybrid Volumetric-Textural Rendering, HVTR [Hu et al. 2022]).
SurMo 可基于重建损失和对抗损失端到端训练,从视频中学习动态人体渲染。
实验结果
该研究在 3 个数据集,共 9 个动态人体视频序列上进行了实验评估: ZJU-MoCap [Peng et al. 2021], AIST++ [Li, Yang et al. 2021] MPII-RRDC [Habermann et al. 2021].
新视点时序渲染
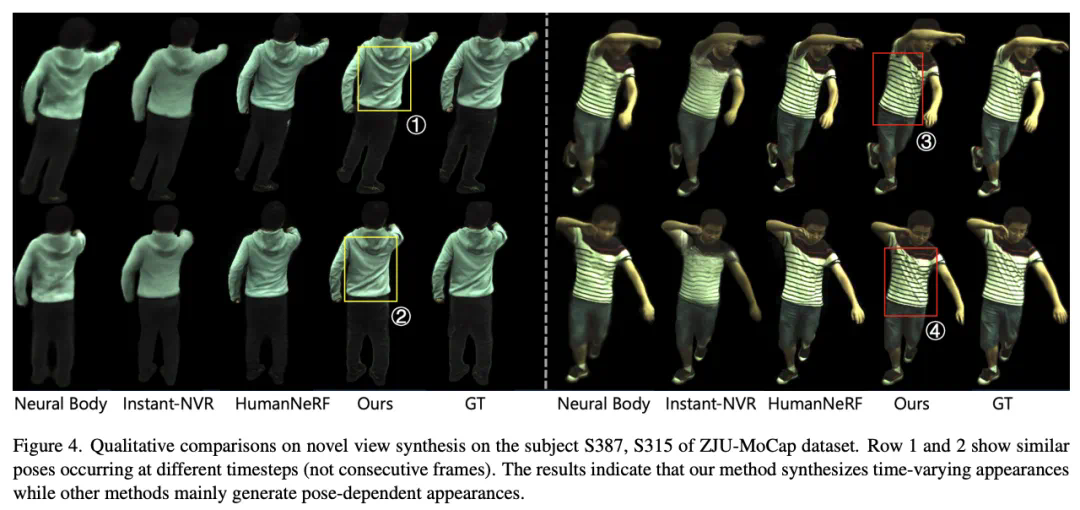
该研究在 ZJU-MoCap 数据集上探究在新视点下对一段时序的动态渲染效果 (time-varying appearances),特别研究了 2 段序列,如下图所示。每段序列包含相似的姿态但出现在不同的运动轨迹中,如①②,③④,⑤⑥。SurMo 可对运动轨迹建模,因此生成随时间变化的动态效果,而相关的 *** 生成的结果只取决于姿态,在不同轨迹下衣服的褶皱几乎一样。

渲染运动相关的阴影及衣服附属运动
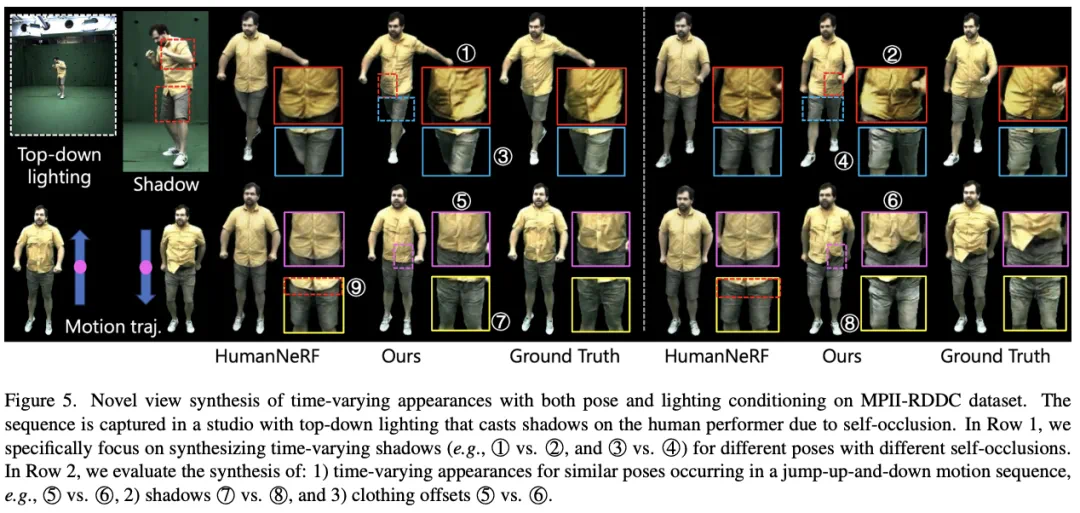
SurMo 在 MPII-RRDC 数据集上探究了运动相关的阴影及衣服附属运动,如下图所示。该序列在室内摄影棚拍摄,在灯光条件下,由于自遮挡问题,表演者身上会出现与运动相关的阴影。
SurMo 在新视点渲染下,可恢复这些阴影,如①②,③④,⑦⑧。而对比 *** HumanNeRF [Weng et al.] 则无法恢复与运动相关的阴影。此外,SurMo 可重建随运动轨迹变化的衣服附属运动,如跳跃运动中不同的褶皱 ⑤⑥,而 HumanNeRF 无法重建该动态效果。
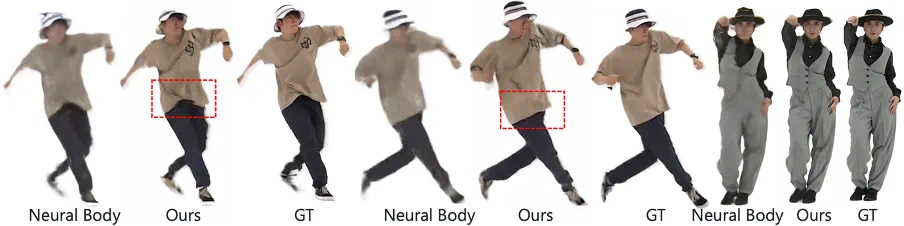
渲染快速运动的人体
SurMo 也从快速运动的视频中渲染人体,并恢复与运动相关的衣服褶皱细节,而对比 *** 则无法渲染出这些动态细节。
消融实验
(1)人体表面运动建模
该研究对比了两种不同的运动建模方式:目前常用的在体素空间 (Volumetric space) 的运动建模,以及 SurMo 提出的在人体表面流形场的运动建模 (Surface manifold) ,具体比较了 Volumetric triplane 与 Surface-based triplane,如下图所示。
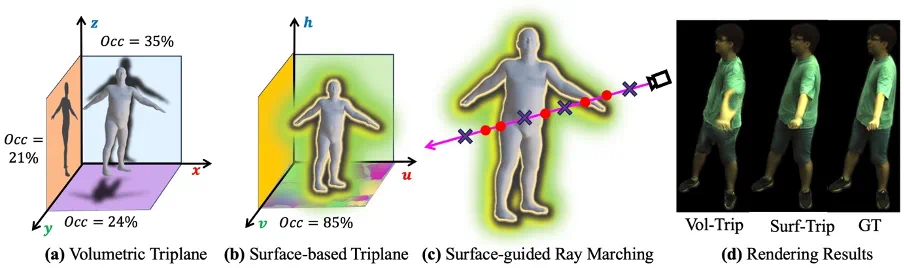
可以发现,Volumetric triplane 是一种稀疏表达,仅有大约 21-35% 的特征用于渲染,而 Surface-based triplane 特征利用率可达 85%,因此在处理自遮挡方面更有优势,如(d)所示。同时 Surface-based triplane 可通过体素渲染中过滤部分远离表面的点实现更快的渲染,如图(c)所示。
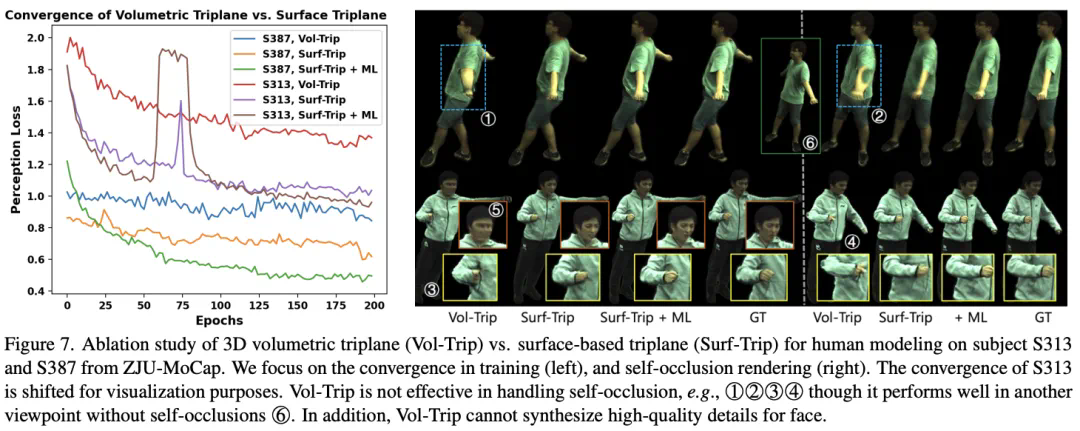
同时,该研究论证 Surface-based triplane 可比 Volumetric triplane 在训练过程收敛更快,在衣服褶皱细节、自遮挡上均有明显优势,如上图所示。
(2)动力学学习
SurMo 通过消融实验研究了运动建模的效果,如下图所示。结果显示,SurMo 可解耦运动的静态特性(如某一帧下固定姿态)及动态特性(如速度)。例如当改变速度的时候,贴身衣服褶皱不变,如①,而宽松衣服褶皱则受速度影响较大,如②,这与日常人们的观测相一致。

本文由 @小畔畔 于2024-04-22发布在 畔畔网,如有疑问,请联系我们。