








微软公布 Text To Speech Avatar AI 工具:可 *** 虚拟 3D 数字人、基于 Azure 平台
- 创业科技
- 2023-12-09
- 6
- 更新:2023-12-09 14:08:25
微软表示,用户使用 Azure AI Speech text to speech (TTS) avatar,可以建立基于“输入文字说出内容”的虚拟化身,并结合现实人物照片训练,建立以真实人物为基础的“互动式聊天机器人”,可用于企业的营销、业务或客户服务等场景。
IT之家11 月 16 日消息,微软在 Ignite 大会中,为 Azure AI Speech 推出了一项名为“Azure AI Speech text to speech (TTS) avatar”的 AI 工具,号称可以生成人类逼真虚拟化身(数字人),目前这款工具已经开放给大众预览试用。
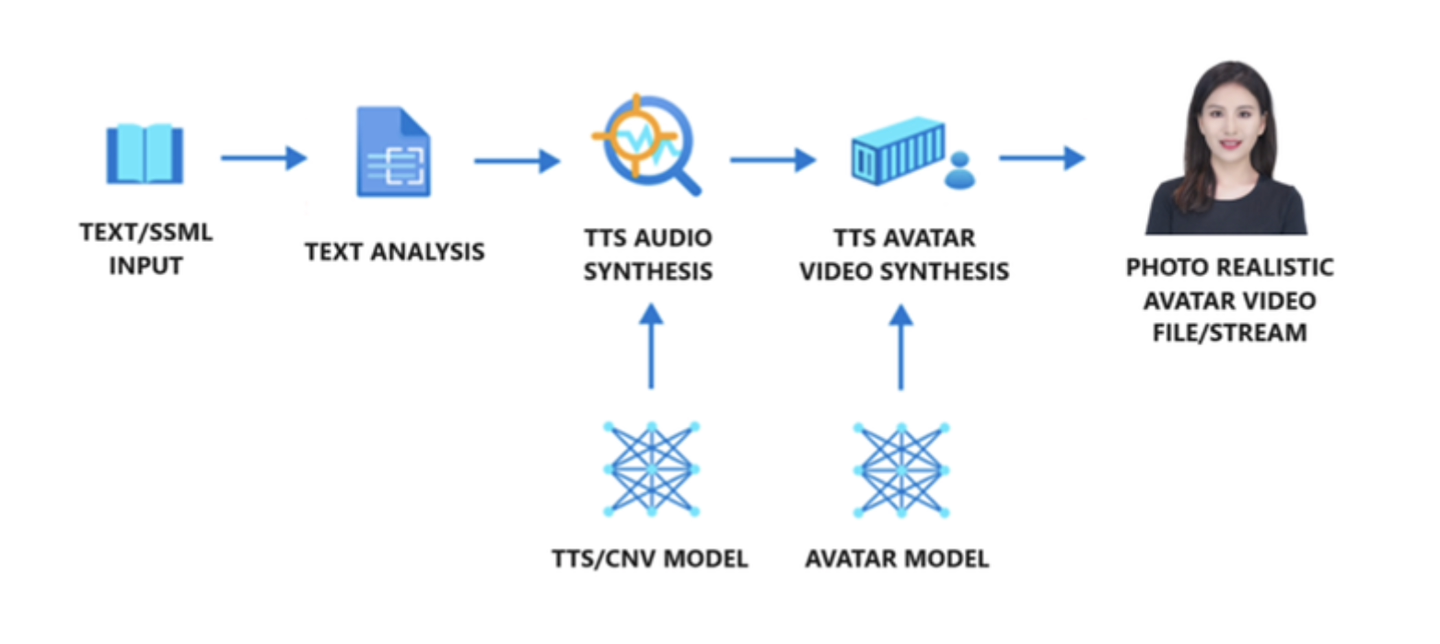
微软表示,用户使用 Azure AI Speech text to speech (TTS) avatar,可以建立基于“输入文字说出内容”的虚拟化身,并结合现实人物照片训练,建立以真实人物为基础的“互动式聊天机器人”,可用于企业的营销、业务或客户服务等场景。
据悉,这项 Azure AI Speech text to speech (TTS) avatar 主要包含三个模块,分别是文字分析器、TTS 声音合成器及 TTS 虚拟化身合成器:
文字分析器会先分析用户输入的文字内容,产生音素序列(phoneme sequence)。接着 TTS 声音合成器中的 TTS 语音模型会预测用户输入文字的声学特征,再合成声音。最后,由神经 *** 声音合成模型 Avatar,根据上述声学特征预测人物的唇形影像,最终形成虚拟化身影像。
微软解释,传统虚拟化身 *** 费时耗工,需要建立专用拍摄环境、而拍摄剪辑后期过程也相当花成本。而当下运用微软最新的 Azure AI Speech text to speech (TTS) avatar 服务,在初次建立模型后,用户只要输入文字就可以 *** 各种产品介绍、互动视频等。配合微软 Azure OpenAI Service 及神经 *** TTS 功能,还能呈现更自然的互动体验。
IT之家发现,微软举例声称,用户可利用 Azure AI Speech TTS avatar 批量 *** 各种视频内容,例如企业文化影片、产品介绍或 CEO 在大会上的数字分身。也可以 *** 虚拟直播数字人、聊天机器人、业务机器人、或线上教学的 AI 老师等。

微软表示,Azure AI Speech text to speech (TTS) avatar 目前已经向 Azure 订阅用户推出,支持各种语言,用户可以从预设的虚拟化身选项中挑选想要的角色,也可以自行定制虚拟化身。
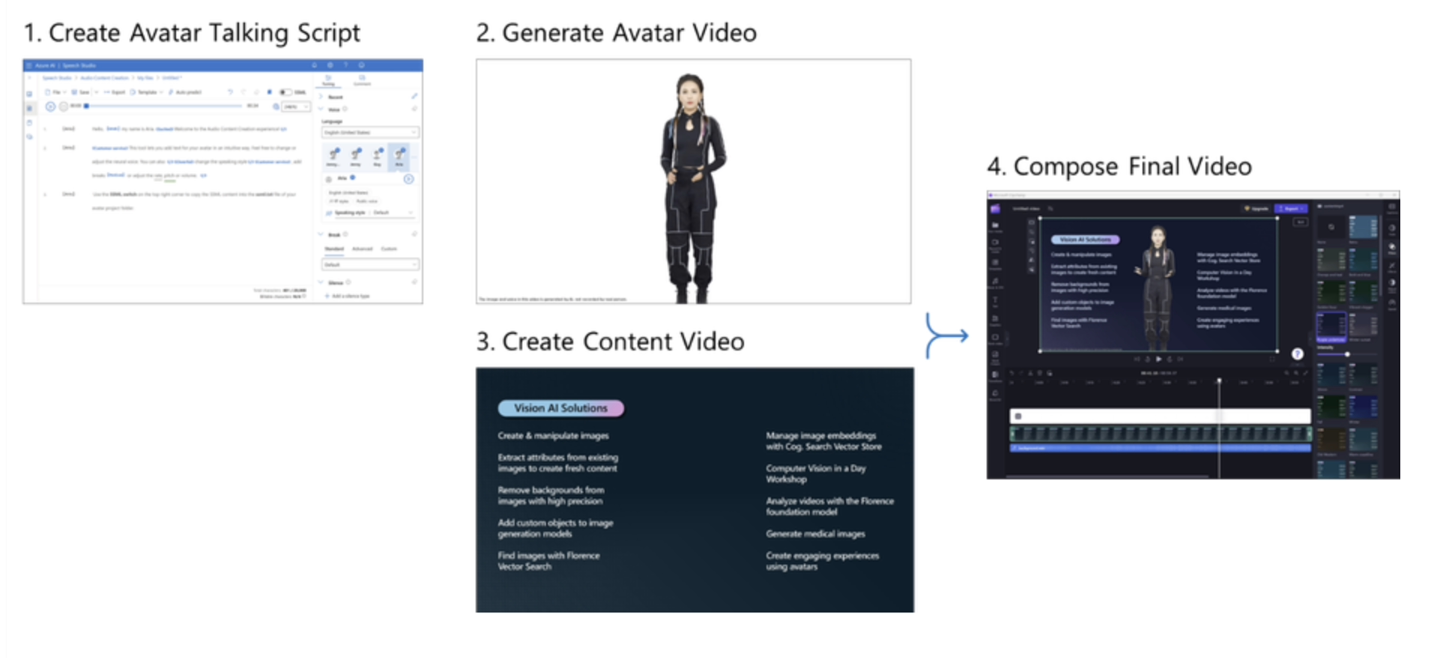
如果用户想要自行定制虚拟化身,则需要上传一批人物视频片段,Azure平台就会在线上处理这些视频,从而生成虚拟化身。角色本身与音源分开,用户可以选择官方提供的默认音源,也可以自行上传训练音源。
本文由 @小畔畔 于2023-12-09发布在 畔畔网,如有疑问,请联系我们。