





NeurIPS 2023 | 腾讯AI Lab 18篇入选论文解读
- 创业科技
- 2023-12-09
- 10
- 更新:2023-12-09 14:08:19
NeurIPS 2023(Neural Information Processing Systems)神经信息处理系统大会是当前全球最负盛名的AI学术会议之一,将于12月10日在美国新奥尔良召开。根据官网邮件显示,本届会议共有12343篇有效论文投稿,接收率为 26.1%,高于 2022 年的 25.6%。
今年腾讯 AI Lab 共有18篇论文入选,包含一篇 Spotlight,内容涵盖机器学习、计算机视觉、自然语言处理等方向,以及AI在科研、游戏等领域的融合探索。
以下为论文概览。
机器学习
1.GADBench: Revisiting and Benchmarking Supervised Graph Anomaly Detection
GADBench:重新审视和基准测试监督图异常检测
论文链接:https://arxiv.org/abs/2306.12251
本文由AI Lab主导,和香港科技大学(广州)合作完成。传统的图异常检测(GAD)算法和最近流行的图神经 *** (GNN)有着悠久的历史,但目前尚存在三个问题:1)它们在标准综合设置下的性能如何;2)GNN是否优于传统的算法,如树集成;3)它们在大规模图上的效率如何。
基于此,本文引入了GADBench;;一个专门用于静态图中监督异常节点检测的基准工具。GADBench有助于在10个真实世界的GAD数据集上进行29种不同模型的详细比较,包括数千到数百万(~ 6M)个节点。本文的主要发现是,具有简单邻域聚合的树集成可以优于为GAD任务量身定制的最新GNN。本文阐明了 GAD 当前的进展,并系统地评估了图异常检测算法,为后续图异常检测研究提供了系统的基准测试标准。
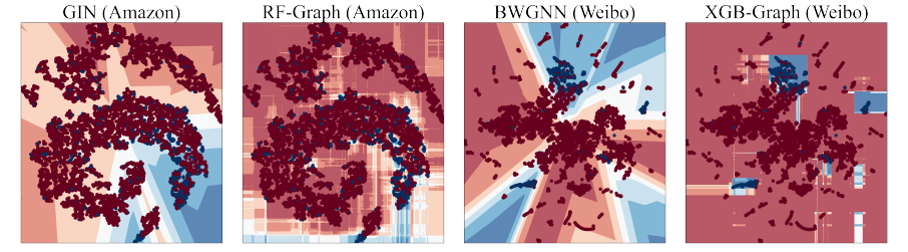
不同 *** 的决策边界比较。 蓝点代表异常节点,红点代表正常节点。 同样,蓝色/红 *** 域对应于异常/正常类的模型预测
2.Does Invariant Graph Learning via Environment Augmentation Learn Invariance?
图不变学习真的学到了不变性吗?
论文链接:https://openreview.net/forum?id=EqpR9Vtt13
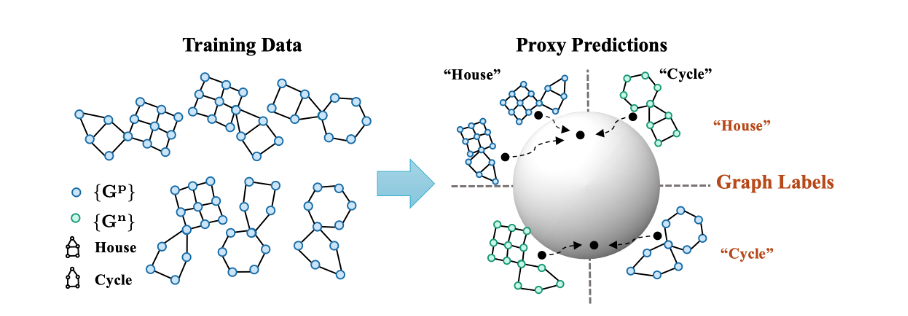
本文由腾讯AI Lab主导,与香港中文大学和香港浸会大学合作完成。不变图表示学习旨在学习来自不同环境/域的图数据之间的不变性,以便于图上的分布外泛化。由于图环境划分通常难以获得,因此现有的 *** 大多通过增强环境信息来弥补这一缺陷。然而,现有各类算法增强得到的环境信息的有效性从未得到验证。
在这项工作中,作者团队发现通过环境增强来学习不变图表示,在没有额外假设的情况下根本是不可能的。为此,本文开发了一套最小假设,包括变化充分性和变化一致性。然后,本文提出了一个新框架;;图不变学习助手(GALA)。GALA包含一个需要对图环境变化或分布变化敏感的助手模型,助手模型的 *** 预测的正确性因此可以区分杂散子图中的变化。
通过提取对 *** 预测更大限度不变的子图,该 *** 可以在建立的最小假设下证明地识别出成功的分布外泛化所需的基础不变子图。在包括DrugOOD在内的各种图分布变化的数据集上进行的广泛实验证实了GALA的有效性,可以解决AI辅助制药中的分布变化问题。
3.Understanding and Improving Feature Learning for Out-of-Distribution Generalization
理解并提升分布外泛化中的特征学习
论文链接:https://openreview.net/forum?id=eozEoAtjG8
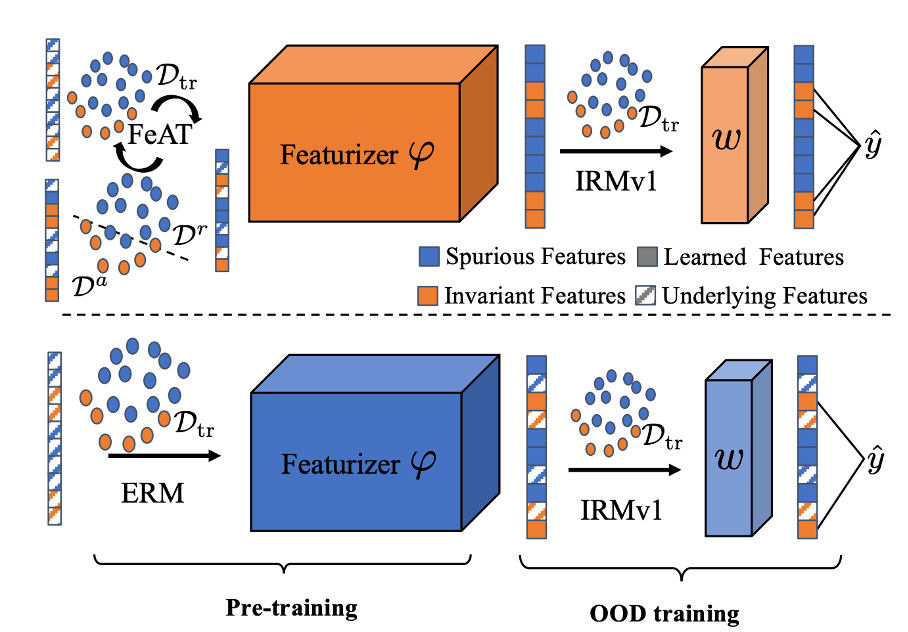
本文由腾讯AI Lab主导,与香港中文大学、RIKEN AIP、香港浸会大学合作完成。对于分布外(OOD)泛化失败的常见解释是,采用经验风险最小化(ERM)训练的模型学习了虚假特征而不是不变特征。然而,最近的几项研究对这一解释提出了挑战,并发现深度 *** 可能已经学习了足够好的特征以进行OOD泛化。
尽管乍一看似乎存在矛盾,但本文理论上展示了ERM本质上学习了虚假特征和不变特征,而如果虚假相关性更强,ERM倾向于更快学习虚假特征。此外,当使用ERM学习的特征进一步进行使用OOD目标进行训练时,不变特征学习的质量显著影响最终的OOD性能,因为OOD目标很少学习新特征。因此,ERM特征学习可能成为OOD泛化的瓶颈。
为了减轻这种依赖,本文提出了特征增强训练(FeAT),以促使模型学习更丰富的特征,为OOD泛化做好准备。FeAT迭代地增强模型以学习新特征,同时保留已经学习的特征。在每一轮中,保留和增强操作在捕获不同特征的训练数据的不同子集上进行。广泛的实验证明,FeAT有效地学习了更丰富的特征,从而提高了各种OOD目标的性能。
4.Retaining Beneficial Information from Detrimental Data for Neural Network Repair
基于有益信息提纯的模型修复算法
论文链接:https://openreview.net/pdf?id=BJ1vOqh2hJ
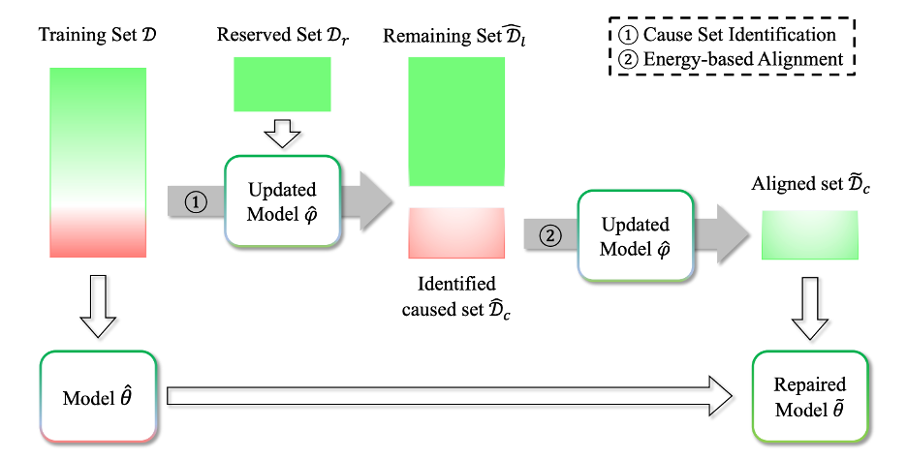
本文由腾讯AI Lab 主导,与香港中文大学合作完成。深度学习模型的表现很大程度上取决于训练数据的质量。训练数据的不足之处,如损坏的输入或带有噪声的标签,可能导致模型泛化能力不佳。近期的研究提出,通过找出导致模型失效的训练样本并消除它们对模型的影响,可以修复模型。然而,被识别出的数据可能同时包含有益和有害信息。简单地从模型中删除被识别数据的信息可能会对其性能产生负面影响,尤其是当正确的数据被误认为是有害的并被移除时。
为了应对这一挑战,本文提出了一种新颖的 *** ,利用保留下来的干净数据集中的知识。该 *** 首先利用干净数据集来识别有害数据,然后在被识别的数据中区分有益和有害信息。最后,本文利用提取出的有益信息来提升模型的性能。通过实证评估,该 *** 在识别有害数据和修复模型失效方面优于基准 *** ;特别是在识别困难且涉及大量良性数据的场景中,该 *** 在保留有益信息的同时提高了性能,而基准 *** 由于错误地删除有益信息而性能下降。
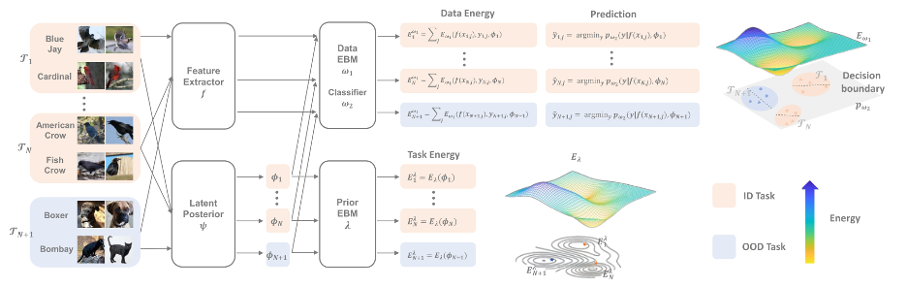
5.Secure Out-of-Distribution Task Generalization with Energy-Based Models
基于能量模型的元学习算法
论文链接:https://openreview.net/pdf?id=tt7bQnTdRm
本文由腾讯AI Lab与香港城市大学,麻省理工大学合作完成。元学习在处理现实中的分布外(OOD)任务时,其成功率并不稳定。为了确保元学习中获得的先验知识能够有效地应用到 OOD 任务上,特别是在注重安全的应用时,往往需要先检测出 OOD 任务,然后再将这些任务调整以适应先验知识。然而,现有的贝叶斯元学习 *** 在评估 OOD 任务的不确定性时,由于特征分布偏移的覆盖不全和元学习先验的表达能力不足,其可靠性受到了限制。此外,这些 *** 在调整 OOD 任务时也面临困难,这与跨领域任务调整解决方案的情况相似,后者容易出现过拟合的问题。
因此,本文构建了一个统一的框架,既可以检测和调整 OOD 任务,又可以与现有的元学习框架兼容。本文提出的基于能量的元学习(EBML)框架,通过两个表达能力强的神经 *** 能量函数的组合,学习描述任意元训练任务分布。本文将这两个能量函数的和作为检测 OOD 任务的可靠评分;在元测试阶段,通过最小化能量来将 OOD 任务调整为分布内的任务。在四个回归和分类数据集上进行的实验证明了该 *** 的有效性。
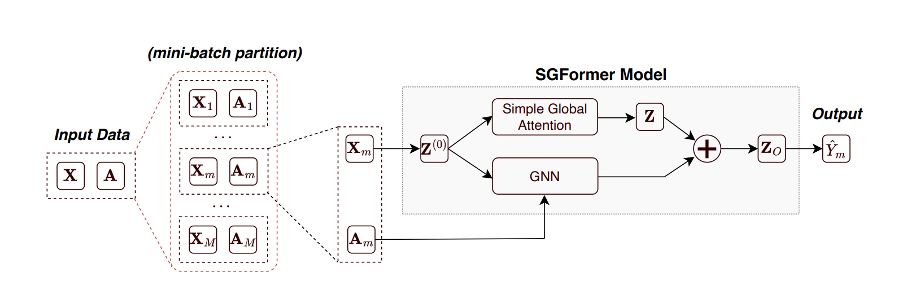
6.Simplifying and Empowering Transformers for Large-Graph Representations
用于大图表示学习的简化且强大的 Transformer 架构
论文链接: https://openreview.net/forum?id=R4xpvDTWkV
本文由腾讯AI Lab与上海交通大学,伊利诺伊大学厄巴纳-香槟分校和纽约大学合作完成。由于海量数据点之间存在相互依赖的性质,学习大型图上的表示是一个长期存在的挑战。Transformer 作为一类新兴的图结构数据基础编码器,由于其全局注意力能够捕获相邻节点之外的所有对影响,因此在小图上表现出了良好的性能。即便如此,现有的 *** 倾向于继承 Transformer 在语言和视觉任务中的特点,并通过堆叠深度多头注意力来拥抱复杂的模型。
本文批判性地证明,即使使用单层注意力也可以在节点属性预测基准上带来令人惊讶的性能,其中节点数量范围从千级到十亿级。这激发作者重新思考大图上 Transformer 的设计理念,其中全局注意力是阻碍可扩展性的计算开销。本文将所提出的方案设计为Simplified Graph Transformers(SGFormer),它由一个简单的注意力模型支持,可以在一层中的任意节点之间有效地传播信息。SGFormer 不需要位置编码、特征/图预处理或增强损失。根据实验,SGFormer 成功扩展到 *** 规模图 ogbn-papers100M,并在中型图上比 SOTA Transformer 产生高达 141 倍的推理加速。除了当前的结果之外,本文所提出的 *** 本身预计将启发在大图上构建 Transformer 的独立兴趣的新技术路径。
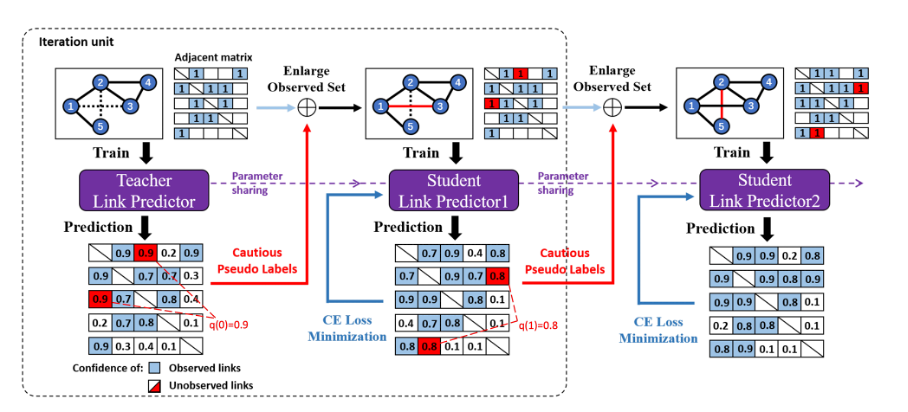
7.Deep Insights into Noisy Pseudo Labeling on Graph Data
深入理解图形数据中噪声伪标签
论文链接:https://openreview.net/pdf?id=XhNlBvb4XV
本文由腾讯AI Lab与香港科学大学(广州)合作完成。伪标签(PL)是一种广泛应用的训练策略,通过在训练过程中对潜在样本进行自我标注,从而扩大标记数据集。许多研究表明,这种 *** 通常可以提高图学习模型的性能。然而,本文作者注意到错误的标签可能对图训练过程产生严重影响。不恰当的 PL 可能导致性能下降,尤其是在噪声可以传播的图数据上。令人惊讶的是,文献中很少对相应的错误进行理论分析。
本文旨在深入探讨 PL 在图学习模型中的作用。首先,本文通过展示 PL 阈值的置信度和多视图预测的一致性来分析 PL 策略的误差。接着,本文从理论上阐述了 PL 对收敛性质的影响。基于这些分析,本文提出了一种谨慎的伪标签 *** ,且为具有更高置信度和多视图一致性的样本添加伪标签。最后,大量实验表明,本文所提出的策略改进了图学习过程,并在链接预测和节点分类任务上优于其他 PL 策略。
计算机视觉
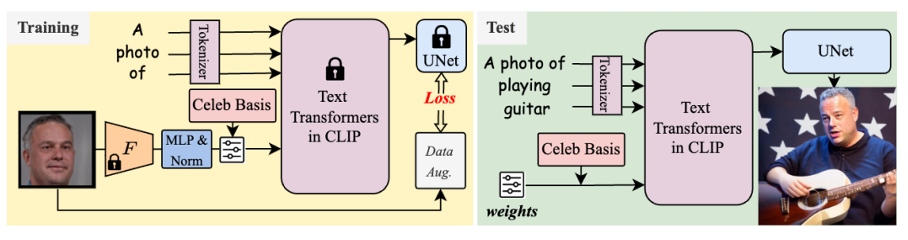
8.Inserting Anybody in Diffusion Models via Celeb Basis
在扩散模型中插入任何人
论文链接:https://openreview.net/pdf?id=OGQWZ3p0Zn
本文由腾讯AI Lab主导,与中山大学、香港科技大学合作完成。精美的需求存在于定制预训练的大型文本到图像模型,以生成创新概念,如用户自身。然而,在训练期间给定几张图像后,与原始概念相比,先前定制 *** 中新增加的概念往往显示出较弱的组合能力。
因此,本文提出了一种新的个性化 *** ,允许使用一个面部段落和仅1024个参数在3分钟内无缝集成独特个体到预训练的扩散模型中。该 *** 可以毫不费力地从文本提示中生成这个人在任何姿势或位置、与任何人互动和做任何可想象的事情的惊人图像。为实现这一目标,本文首先分析并从预训练的大型文本编码器的嵌入空间中构建一个明确的名人基础。然后,给定一张面部照片作为目标身份,通过优化该基础的权重并锁定所有其他参数来生成其自身的嵌入。在该定制模型中,由所提议的名人基础赋予的新身份展示出比以前的个性化 *** 更好的概念组合能力。此外,该模型还可以一次学习多个新身份并相互交互,而以前的定制模型无法实现这一点。
9.DeepfakeBench: A Comprehensive Benchmark of Deepfake Detection
DeepfakeBench:深度伪造检测的全面基准测试
论文链接:https://openreview.net/forum?id=hizSx8pf0U
本文由腾讯AI Lab主导,与香港中文大学(深圳)、美国纽约州立大学布法罗分校合作完成。 在深度伪造检测(Deepfake)领域,一个关键但经常被忽视的挑战是缺乏一个标准化、统一、全面的基准。这个问题导致了不公平的性能比较和可能产生误导的结果。具体来说,数据处理流程缺乏一致性,导致检测模型的数据输入不一致。此外,实验设置存在明显差异,评估策略和指标缺乏标准化。
为了填补这一空白,本文提出了之一个全面的深度伪造检测基准,称为DeepfakeBench,它提供了三个关键贡献:1)一个统一的数据管理系统,以确保所有检测器的输入一致;2)一个集成的更先进 *** 实现框架;3)标准化的评估指标和协议,以促进透明度和可重复性。DeepfakeBench具有可扩展、基于模块的代码库,包含15种更先进的检测 *** 、9个深度伪造数据集、一系列深度伪造检测评估协议和分析工具,以及全面的评估。此外,本文还从各种角度(如数据增强、主干 *** )对这些评估进行了广泛分析,提供了新的见解,以期在该关键的领域推动创新。
基准测试代码、评估和分析已开源:https://github.com/SCLBD/DeepfakeBench。
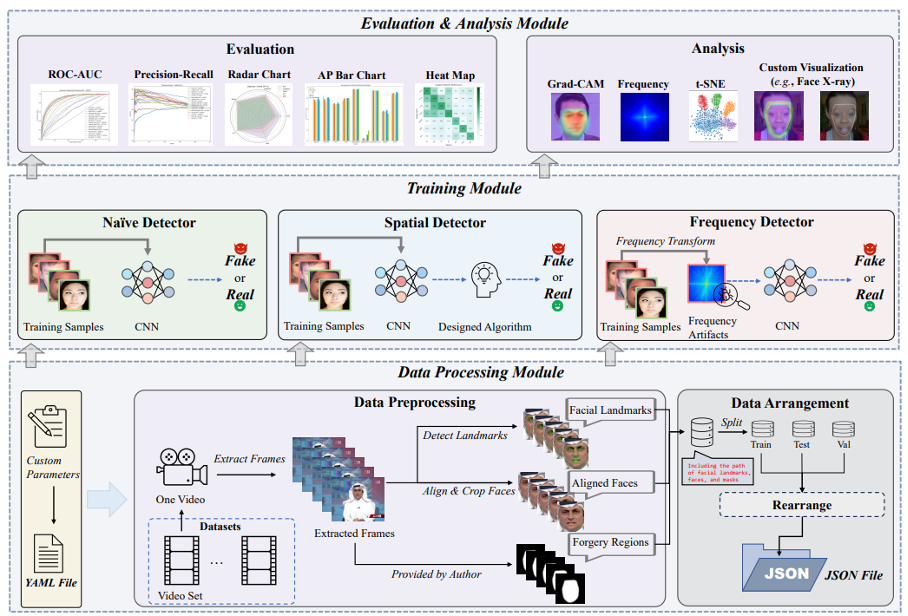
10 .GPT4Tools: Teaching Large Language Model to Use Tools via Self-instruction
GPT4Tools: 基于自指引教授大语言模型使用工具
论文链接:https://openreview.net/pdf?id=cwjh8lqmOL
本文由腾讯AI Lab主导,与清华大学深圳研究生院、香港中文大学合作完成。这篇论文的目的是为了高效地使大型语言模型(LLMs)能够使用多模态工具。像ChatGPT和GPT-4这样的高级专有LLMs已经通过复杂的提示工程显示出了使用工具的巨大潜力。然而,这些模型通常依赖于高昂的计算成本和公众无法获取的数据。
为了解决这些挑战,本文提出了基于自我指导的GPT4Tools,使开源LLMs(如LLaMA和OPT)能够使用工具。该 *** 通过向一位高级教师提示多种多模态情境,生成了一个指令跟随数据集。通过使用低秩适应(LoRA)优化,该 *** 帮助开源LLMs解决一系列视觉问题,包括视觉理解和图像生成。此外,本文提供了一个基准测试来评估LLMs使用工具的能力,这种测试既包括零次射击方式,也包括微调方式。广泛的实验表明,该 *** 对各种语言模型都有效,不仅显著提高了调用已见工具的准确性,还实现了对未见工具的零次射击能力。
代码和演示链接:https://github.com/AILab-CVC/GPT4Tools
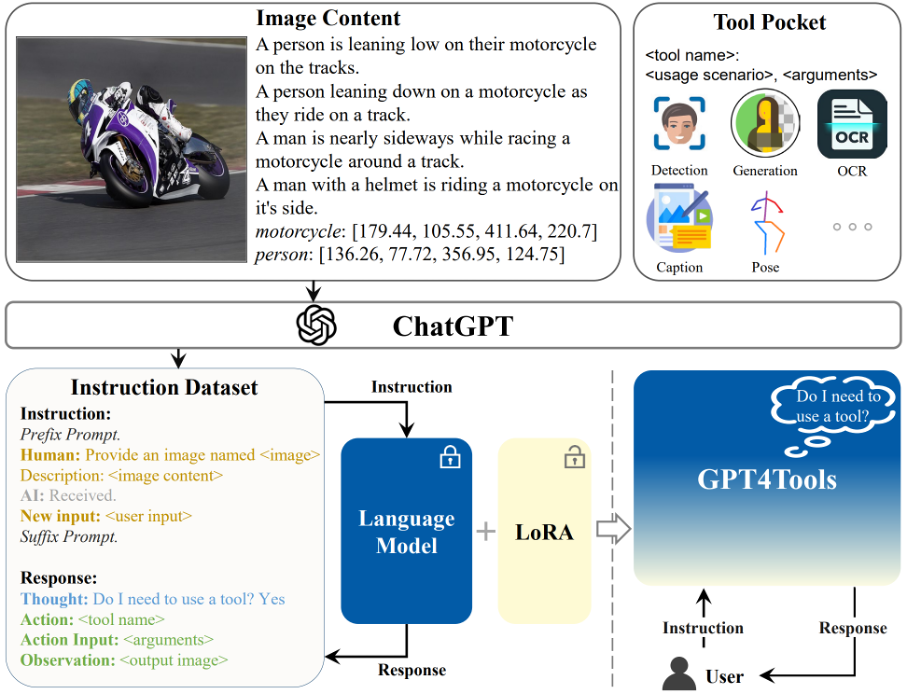
11.Meta-Adapter: An Online Few-shot Learner for Vision-Language Model
Meta-Adapter: 面向视觉语言模型的在线小样本学习网路
论文链接:https://openreview.net/pdf?id=Ts0d8PvTeB
本文由腾讯AI Lab主导,与西安交通大学合作完成。本文介绍的对比式视觉语言预训练,即CLIP,显示出在理解开放世界视觉概念方面的显著潜力,使得零样本图像识别成为可能。然而,基于CLIP的少样本学习 *** 通常需要在少量样本上离线微调参数,这导致推理时间延长和在某些领域过拟合的风险。
为了应对这些挑战,本文提出了一种轻量级的残差式适配器;;Meta-Adapter,通过少量样本在线方式指导优化CLIP特征。只需少量训练样本,该 *** 就能有效开启少样本学习能力,并在未见数据或任务上实现无需额外微调的泛化,取得了具有竞争力的性能和高效率。该 *** 无需额外复杂操作,在八个图像分类数据集上平均超过最新的在线少样本学习 *** 3.6%,且具有更高的推理速度。此外,该模型简单灵活,可作为直接适用于下游任务的即插即用模块。在无需进一步微调的情况下,Meta-Adapter在开放词汇目标检测和分割任务中取得了显著的性能提升。
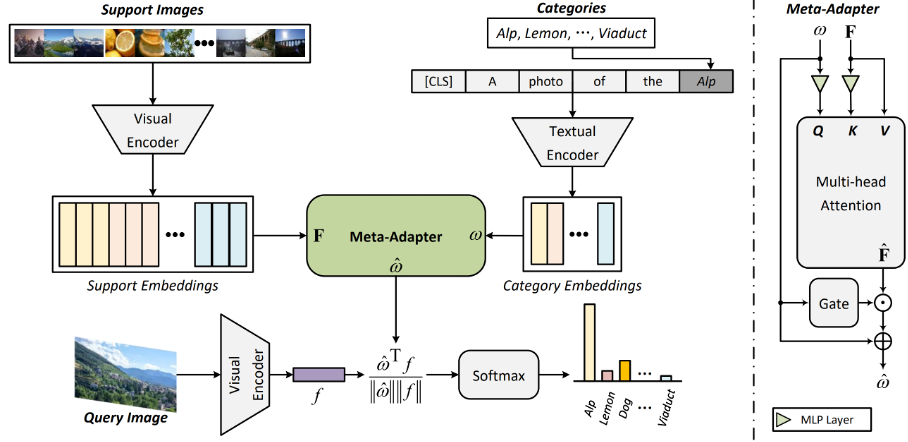
自然语言处理
12.Fairness-guided Few-shot Prompting for Large Language Models
公平引导的大语言模型上下文提示 ***
论文链接:https://arxiv.org/abs/2303.13217
本文由腾讯AI Lab主导,与天津大学,新加坡科技研究局(A*STAR)合作完成。大型语言模型展示了惊人的能力,可以进行上下文学习,即这些模型可以通过依据少量输入-输出示例构建的提示来直接应用于解决众多下游任务。然而,先前的研究表明,由于训练示例、示例顺序和提示格式的变化,上下文学习可能会遭受高度不稳定的问题。因此,构建适当的提示对于提高上下文学习的性能至关重要。
本文从预测偏差的角度重新审视这个问题。具体而言,本文引入了一个度量标准来评估固定提示相对于标签或给定属性的预测偏差。通过实验证明,具有更高偏差的提示总是导致不令人满意的预测质量。基于这一观察,本文提出了一种基于贪婪搜索的新型搜索策略,用于识别接近更优的提示,以提高上下文学习的性能。通过对包括GPT-3在内的更先进的主流模型进行了全面实验(涉及各种下游任务),结果表明,该 *** 可以以一种有效且可解释的方式增强模型的上下文学习性能,使大语言模型的表现更加可靠。
13.Repetition In Repetition Out: Towards Understanding Neural Text Degeneration from the Data Perspective
Repetition In Repetition Out: 从数据角度理解神经 *** 文本生成中的退化问题
论文链接:https://openreview.net/pdf?id=WjgCRrOgip
本文由腾讯AI Lab与奈良先端科学技术大学院大学、剑桥大学、Cohere合作完成。关于神经 *** 文本生成中的退化问题(即语言模型倾向于生成重复和陷入循环)存在许多不同的假设,使得这个问题既有趣又令人困惑。本文从数据的角度理解这个问题,并提供了一个简单而基本的解释。研究显示,退化问题与训练数据中的重复的相关性很强。实验表明,通过在训练数据中有选择地减少对重复的关注,可以显著减少退化。此外,以往从不同立场(如高流入词、更大似然目标和自我强化)出发的假设可以用本文提出的简单解释来统一。也就是说,惩罚训练数据中的重复是它们有效性的共同基础。实验表明,即使在更大的模型尺寸和指令微调后,惩罚训练数据中的重复仍然至关重要。
 游戏AI
游戏AI
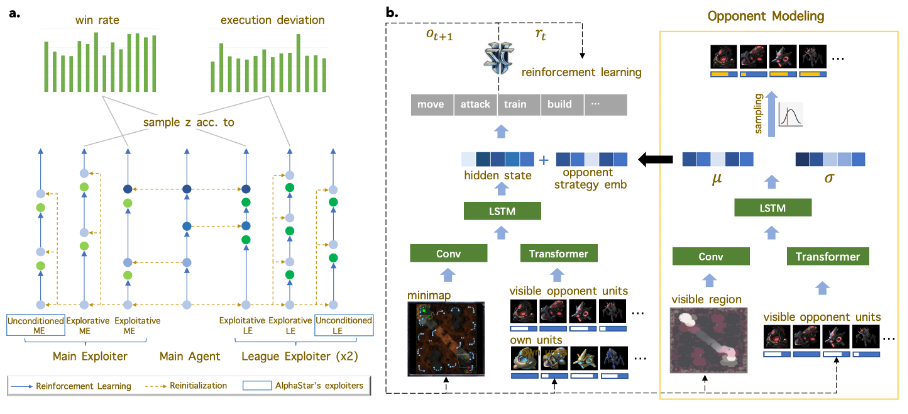
14.A Robust and Opponent-Aware League Training Method for StarCraft II
一种鲁棒且具有对手认知的星际争霸2联盟训练 ***
论文链接:https://openreview.net/pdf?id=tDAu3FPJn9
本文由腾讯AI Lab独立完成,已被会议接收为Spotlight。在星际争霸2(星际2)这种大型RTS游戏中训练一个超乎常人水平的AI是极其困难的。受博弈论 *** 启发,AlphaStar提出了一种联盟训练框架(league training framework),成为首个在星际2中击败人类职业玩家的AI。
本文从两个重要的方面对AlphaStar的联盟训练进行改进。该项工作使用了目标趋向的利用者(goal-conditioned exploiters)来增强AlphaStar中的无目标的利用者(unconditioned exploiters),大大提升了利用者发现主 *** (main agent)和整个联盟弱点的能力;此外,为联盟中的 *** 增加了对手建模能力,使 *** 能更加迅速地响应对手的实时策略。基于这些改进,作者团队用比AlphaStar更少的资源训练出了一个更鲁棒的超越人类玩家水平的AI,与多位顶级职业玩家分别进行的20局比赛中均保持了50%以上的胜率。该研究为大型复杂的两人零和非完美信息博弈场景求解鲁棒策略提供了有价值的参考。
15.Policy Space Diversity for Non-Transitive Games
非传递性博弈游戏中的策略空间多样性
论文链接:https://arxiv.org/pdf/2306.16884.pdf
本文由腾讯AI Lab独立完成。在多智能体非传递博弈中,PSRO是一个影响力强大的算法框架,能够较高效地寻找博弈中的纳什均衡策略。许多先前的研究试图在PSRO中提升策略多样性,然而,大多数此类工作的一个主要不足是,一个更多样(按照他们的定义)的策略 *** 并不一定意味着(如本文中证明的)更高的强度。
为了解决这个问题,本文从策略空间上定义一个新的多样性指标,在训练中通过优化该指标能使模型产生的策略更好地接近NE。同时,本文推导了一种可实践的,基于状态-动作样本的 *** 来优化多样性指标。结合本文提出的多样性指标和原始PSRO算法,可以得到一个新的PSRO变体,策略空间多样性PSRO(PSD-PSRO)。本文在理论上分析了PSD-PSRO的收敛性质,并且通过实验验证PSD-PSRO更能有效地产生低可被利用性的策略。

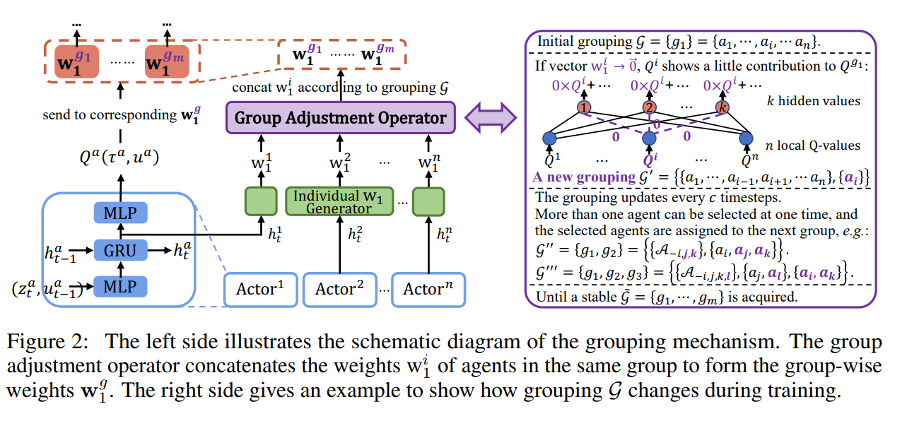
16.Automatic Grouping for Efficient Cooperative Multi-Agent Reinforcement Learning
通过自动分组实现高效协作的多智能体强化学习
论文链接:https://openreview.net/pdf?id=CGj72TyGJy
本文由腾讯AI Lab与中国科学院自动化研究所、清华大学合作完成。分组在自然系统中无处不在,其对于提升团队协调效率至关重要。本文提出了一种新的面向群体的多智能体强化学习,它能够在没有领域知识的情况下学习自动分组以实现有效的合作。与现有的直接学习联合行动价值和个体效用之间复杂关系的 *** 不同,本文将分组作为桥梁来连接各组智能体,并鼓励他们之间的合作,从而提高整个团队的学习效率。
具体来说,该 *** 将联合行动的价值拆解为每一组的价值,这些价值指导智能体以更细粒度的方式提升他们的策略。本文提出了一种自动分组机制来生成动态的分组以及组行动价值。进一步,本文引入了一种用于策略学习的分层控制,该控制驱动同一组中的智能体专门研究类似的策略,并在组间产生多样化的策略。在StarCraft II微管理问题和谷歌足球场景上的实验验证了该 *** 的有效性,并且揭示了分组的工作方式以及如何提高性能。
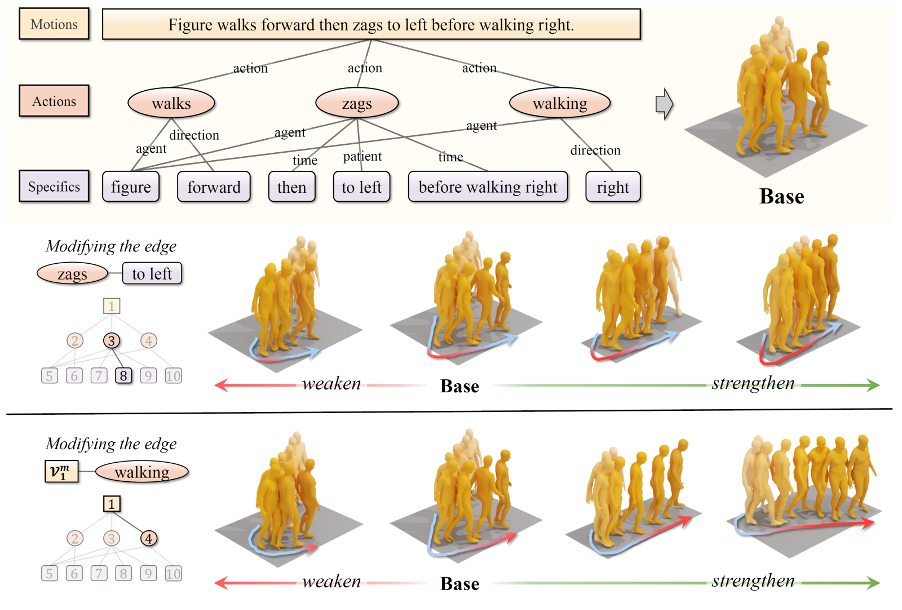
17.Act As You Wish: Fine-Grained Control of Motion Diffusion Model with Hierarchical Semantic Graphs
行动如你所愿:基于层次语义图的精细可控运动扩散模型
论文链接:https://arxiv.org/pdf/2311.01015.pdf
本文由腾讯AI Lab和北京大学合作完成。人体运动生成是游戏影视 *** 、虚拟现实和人形机器人等领域的所必须的关键技术,其目标一般是生成尽可能拟真的人体运动序列。传统的生成管线一般需要专业演员来捕捉运动,并辅以专业动画师细致繁杂的手工精修才能完成。近年,基于状态机或者Motion Matching的动画技术极大推动了人体运动的自动化生成,但仍然存在需人工收集动作片段,内存消耗大,只能做动作片段的组合,可控性有限等问题。因此,基于学习(以神经 *** 为主流)的解决方案,尤其是基于文本的人体运动生成获得了特别的关注并刚刚取得了显著进步。
本文提出了一种新的基于层次化语义图的精细化可控文本生成运动方案GraphMotion。它可根据文本中所指定的运动类别,运动路径,运动风格等信息,生成相应的3D人体骨骼序列。与现有相关方案相比,GraphMotion将输入文本解析为一种新的控制信号:层次语义图,能从粗到精的从三个语义级别来分别捕获与生成人体的整体运动、局部动作和动作细节。GraphMotion在提高结果生成质量(文本匹配准确度、运动逼真度等)的同时也保证了结果的多样性,不仅刷新了SOTA性能,还具备通过调节语义图(改变节点间的权重以及增减修改节点等)来实现前所未有的精细调控生成结果的额外能力。
开源链接:https://github.com/jpthu17/GraphMotion .
AI for Science
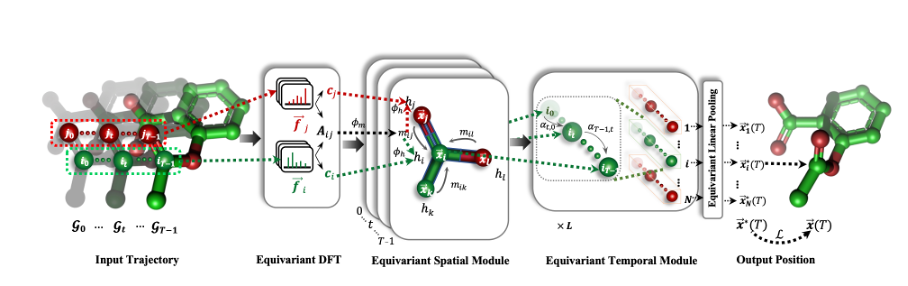
18.Equivariant Spatio-Temporal Attentive Graph Networks to Simulate Physical Dynamics
模拟物理动态的等变时空注意力图 ***
论文链接:https://openreview.net/pdf?id=35nFSbEBks
本文由腾讯AI Lab与中国人民大学合作完成。学习如何表示和模拟物理系统的动态是一项至关重要且富有挑战性的任务。现有的等变图神经 *** (GNN) *** 已经捕捉到了物理学的对称性,例如平移、旋转等,从而具有更好的泛化能力。然而,这些 *** 在处理任务时逐帧进行,忽略了主要由环境中未观察到的动态引起的非马尔可夫特性。
在本文中,该 *** 通过利用过去一段时间的轨迹来恢复非马尔可夫交互,将动态模拟改进为一个时空预测任务。为此,本文提出了一种等变时空注意力图 *** (ESTAG),它是一种等变的时空 GNN。在其核心,本文设计了一种新颖的等变离散傅立叶变换(EDFT),用于从历史帧中提取周期性模式,并构建了一个等变空间模块(E *** )来完成空间信息传递,以及一个具有前向注意力和等变池化机制的等变时间模块(ETM)来整合时间信息。在分别对应于分子、蛋白质和宏观层次的三个真实数据集上的评估表明, ESTAG 与典型的时空 GNN 和等变 GNN 相比具有更高的有效性。
本文由 @小畔畔 于2023-12-09发布在 畔畔网,如有疑问,请联系我们。
上一篇:台式电脑10年了还能用吗
下一篇:蓝屏长按电源键无法关机怎么办