

NeO 360:用于室外场景稀疏视图合成的神经场
- 创业科技
- 2023-11-06
- 11
- 更新:2023-11-06 08:03:06
本文的⽅法扩展了 NeRF++ 使其具有可推广性。⽅法的核⼼是以三平⾯形式表示的局部特征。
本文经自动驾驶之心公众号授权转载,转载请联系出处。
论文:ICCV 2023 https://arxiv.org/pdf/2308.12967.pdf


近期的隐式神经表示在新视角合成方面取得了很好的结果。然而,现有的 *** 需要从大量视角进行昂贵的场景优化,然而现实世界中感兴趣的对象或背景仅从很少的视角观察到,因此限制了这些 *** 在真实世界的无限城市环境中的应用,为了克服这一挑战,本文引入了一种名为NeO 360的新 *** ,用于稀疏视角合成室外场景的神经场表示。NeO 360是一种通用 *** ,可以从单个或少量定姿的RGB图像重建360°场景。该 *** 的精髓在于捕捉复杂现实世界室外3D场景的分布,并使用混合的图像条件三平面表示,可以从任何世界点进行查询。本文的表示结合了基于体素和鸟瞰图(BEV)表示的优点,比每种 *** 都更有效和表达丰富。NeO 360的表示使本文能够从大量的无界3D场景中进行学习,同时在推理过程中对新视角和新场景具有普适性,甚至可以从单个图像中进行推理。本文在提出的具有挑战性的360°无界数据集NeRDS 360上演示了本文的 *** ,并展示了NeO 360在新视角合成方面优于现有的通用 *** ,同时还提供了编辑和合成能力。项⽬主页:zubair-irshad.github.io/projects/neo360.html
主要贡献有哪些?
本文的⽅法扩展了 NeRF++ 使其具有可推广性。⽅法的核⼼是以三平⾯形式表示的局部特征。这种表示被构建为三个垂直的交叉平⾯,其中每个平⾯从⼀个⻆度对 3D 环境进⾏建模,通过合并它们可以实现 3D 场景的全⾯描述。NeO 360 的图像条件三平⾯表示有效地对来⾃图像级特征的信息进⾏编码,同时为任何世界点提供紧凑的可查询表示。本文将这些特征与剩余局部图像级特征相结合,从⼤量图像中优化多个⽆界 3D 场景。NeO 360 的 3D 场景表示可以为完整的 3D 场景构建强⼤的先验,从⽽只需⼏个摆好姿势的 RGB 图像即可实现对户外场景进⾏⾼效的 360°新颖的视图合成。全新⼤型 360°⽆界数据集包含 3 个不同地图上的 70 多个场景。本文在 few-shot 新颖视图合成和基于先验的采样任务中证明了本文的⽅法在这个具有挑战性的多视图⽆界数据集上的有效性。除了学习完整场景的强⼤ 3D表示之外,本文的⽅法还允许使⽤ 3D ground truth边界框对光线进⾏推理时间修剪,从⽽能够从⼏个输⼊视图进⾏组合场景合成。总之,本 *** 出以下贡献:
适⽤于室外场景的通⽤ NeRF 架构基于三平⾯表示来扩展 NeRF 公式,以实现 360 度的有效few-shot新颖视图合成360°⽆界的环境。⼤规模合成360°数据集,称为 NeRDS 360,⽤于 3D 城市场景理解包含多个对象,通过密集的相机视点注释捕获⾼保真室外场景。本文提出的⽅法显着优于 NeRDS 360 数据集上的小样本新颖视图合成任务的所有基线, 有着 3-view novel-view 合成任务的 1.89 PNSR 和 0.11 SSIM 绝对提升值。NeRDS 360 多视角数据集:
为什么构建这个数据集?
获取精确的地面真实 3D 和 2D 信息(如更密集的视点标注、3D 边界框、语义和实例图)具有挑战性,因此可用于训练和测试的户外场景非常有限。之前的方案主要集中在使用现有的户外场景数据集进行重建,这些数据集是安装在自车载体上的摄像头捕获的全景视图。在相邻摄像头视图之间几乎没有重叠部分,而这种特征已被证明对于训练 NeRF 和多视图重建 *** 很有用。随着自车快速移动以及感兴趣的对象在仅几个视图中被观察到(通常小于 5 个),针对这些场景优化基于对象的神经辐射模型变得更加具有挑战性。数据集是怎样的?
为了应对这些挑战,本文提出了⼀个⽤于 3D 城市场景理解的⼤规模数据集。与现有数据集相⽐,本文的数据集由 75 个具有不同背景的户外城市场景组成,包含超过 15,000 张图像。这些场景提供 360°半球形视图,捕捉各种照明条件下照亮的不同前景物体。此外,本文的数据集包含不限于前向驾驶视图的场景,解决了先前数据集的局限性,例如摄像机视图之间有限的重叠和覆盖范围。⽤于泛化评估的最接近的现有数据集是 DTU(80 个场景),主要包含室内物体,不提供多个前景物体或背景场景。
数据集如何生成的?
本文使⽤ Parallel Domain ⽣成合成数据以渲染⾼保真 360° 场景。本文选择 3 个不同的地图,即SF 6thAndMission, SF GrantAndCalifornia and SF VanNessAveAndTurkSt并在所有 3 个地图上采样 75 个不同场景作为本文的背景(3 个地图上的所有 75 个场景都是彼此显着不同的道路场景,在城市的不同视⻆拍摄)。本文选择 50 种不同纹理的 20 辆不同的汽⻋进⾏训练,并从每个场景中的 1 到 4 辆汽⻋中随机采样进⾏渲染。本文将此数据集称为NeRDS 360:NeRF forReconstruction,Decomposition and SceneSynthesis of 360° outdoor scenes。训练集:本文总共⽣成了 15k 个渲染图。通过在距汽⻋中⼼固定距离的半球形圆顶中对 200 个摄像机进⾏采样。测试集:本文提供了 4 辆不同汽⻋和不同背景的 5 个场景进⾏测试,其中包括 100 个均匀分布在上半球的摄像机,与训练时使⽤的摄像机分布不同。

本文使⽤不同的验证相机分布来测试本文的⽅法泛化到训练期间未⻅过的视点以及未⻅过的场景的能⼒。由于遮挡、背景多样性以及具有各种闪电和阴影的渲染对象,本文的数据集和相应的任务极具挑战性。本文的任务需要重建 360° 使⽤少量观察(即 1 到 5)的完整场景的半球形视图,如Figure 5 中 的红⾊摄像机所示。⽽使⽤所有 100 个半球视图进⾏评估,如Figure 5 中的绿⾊摄像机所示。因此,本文的任务需要强⼤的先验知识来合成室外场景的新颖视图。
*** :
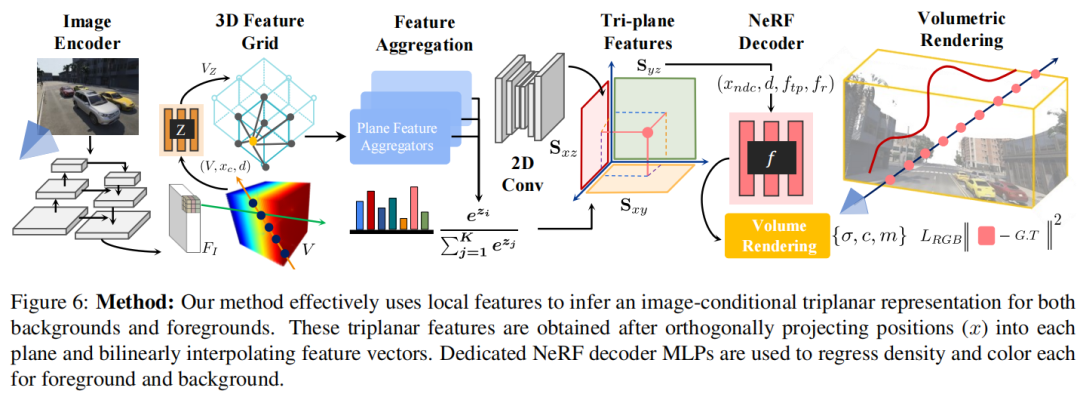
给定新场景的⼏个视图的 RGB 图像,NeO 360 进行新颖视图合成并渲染360度场景的3D场景表示。为了实现这⼀⽬标,本文采⽤了由三平⾯表示组成的混合局部和全局特征表示,可以查询任何世界点。形式上,如Figure 1所示,给定⼀些输⼊图像,的⼀个复杂的场景,其中n=1到5、以及他们相应的相机位子,γγγ其中γ,NeO 360推断近远背景的密度和辐射场(类似于 NeRF++),两者的主要区别是NeO 360使⽤混合局部和全局特征来调节辐射场解码器,⽽不是像经典 NeRF 公式中所采⽤的那样仅使⽤位置和观察⽅向。
Image-Conditional Triplanar Representation(图像条件三平⾯表示)
虽然NeRF能够产⽣⾼保真场景合成,但局限于很难推⼴到新颖场景。为了有效地使⽤场景先验并从⼤量⽆界 360° 数据中学习,本文提出了⼀种图像条件三平⾯表示,这种表示能够对具有完整 表现⼒的 3D 场景进⾏⼤规模建模,⽽不会忽略其任何维度(如在 2D 或基于 BEV 的表示中)并避免⽴⽅复杂性(如在基于体素的表示中)。本文的三平⾯表示由三个轴对⻬的正交平⾯组成,其中是空间分辨率,每个平面具有维特征。为了从输⼊图像构建特征三平⾯, *** 如下:
本文⾸先使⽤经过 ImageNet 预训练的 ConvNet backboneE提取低分辨率空间特征表示,其将原始输入的图像转化为长宽分别变为1/2的特征图。然后根据相机位姿和内参沿着每条射线反投影为3D特征体数据。由于沿相机光线的所有特征在⽹格中都是相同的,因此本文通过额外的 MLP 进⼀步学习各个特征的深度,,它将⽹格中的输入体数据特征、在相机坐标系中的网格位置和在世界坐标系下的网格的方向用concatenated连接转换到相机坐标下输出深度编码特征。接下来通过在独立的体特征维度上使用可学习的权重获得三平⾯特征:其中的代表MLPs特征聚合,代表在维度累加之后的softmax得分。将特征投影到各个平⾯的动机之⼀是避免 3D CNN 的计算⽴⽅复杂性,同时⽐ BEV 或 2D 特征表示更具表现⼒但该类 *** ⽐基于体素的表示在计算上更有效,但省略轴会损害它们的表达能⼒。相反,本文依靠 2D 卷积将构建的图像条件三平⾯转换为新的通道输出,其中、同时对平⾯的空间维度进⾏上采样到图像特征空间。学习到的卷积充当修复⽹络来填充缺失的特征。本文的三平⾯表示充当全局特征表示,因为直观上,从不同⻆度检查时可以更好地表示复杂场景。这是因为每个都可以提供补充信息,可以帮助更有效地理解场景。Deep Residual Local Features (深层残差局部特征)
对于接下来的辐射场解码阶段,本文还使⽤特征作为渲染 MLP 的残差连接。本文获得从通过投影世界点使⽤其相机参数γ进⼊源视图,并通过双线性插值在投影像素位置提取特征。请注意,局部和全局特征提取路径共享相同的权重θ和编码器。本文发现,对于复杂的城市⽆界场景,仅使⽤局部特征导致遮挡和远处 360° 视角表现不佳。另⼀⽅⾯,仅使⽤全局特征会导致幻觉。本文的⽅法有效地结合了局部和全局特征表示,从⽽产⽣更准确的 360° 从最⼩的⽆限场景的单⼀视图进⾏视图合成。
Decoding Radiance Fields(解码辐射场)
辐射场解码器是用来预测颜⾊和密度σ对于任意 3D 位置和任意观看⽅向从三平⾯和残差特征。本文使⽤模块化实现的渲染 MLP。MLP 表示为:
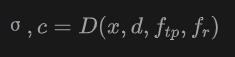
其中,通过正交投影点进⼊每个平⾯并执⾏双线性采样获得,且由三个双线性采样向量连接成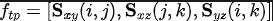
。本文使用输入图像的视图空间来建立本文的坐标系,然后在这个特定的坐标系中展示位置和摄像机射线。Near and Far Decoding MLPs类似于NeRF++,本文定义了两个渲染MLP来解码颜⾊和密 度信息,如下所示:
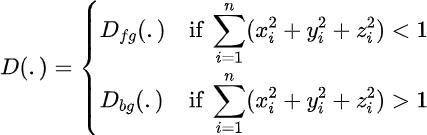
本文定义⼀个坐标重映射函数 (M) 类似于原始 NeRF++收缩位于单位球体之外的 3D 点, 这有助于更多对象在渲染 MLP 中获得较低的分辨率。在查询阶段的三平⾯表示,本文使⽤在现实世界坐标中的⾮收缩坐标,因为本文的表示是平⾯⽽不是球体。对于渲染,本文使⽤各⾃的放缩后的坐标⽤于调节 MLP。Optimizing radiance fields for few-shot novel-view synthesis给定源视图的局部和全局特征,在完成体积渲染和合成近处和远处背景后,使用专用的解码颜色和强度近背景和远背景MLPs解码器和
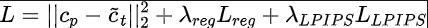
:⽬标图像中采样的像素位置:从近和远的MLPs渲染输出中获得的合成颜色。
Scene Editing and Decomposition(场景编辑与分解)
给定从检测器获得的 3D 边界框,本文可以通过简单地对对象的 3D 边界框内的光线进⾏采样,获得单个对象和背景辐射率,并在这些特定的处双线性插值特征在本文的三平⾯特征⽹格中的位置,使得编辑和重新渲染单个对象变得简单。本文通过考虑对象 3D 边界框 内的特征来执⾏准确的对象重新渲染,以渲染前景MLP。本质上,本文将组合的可编辑场景渲染公式划分为渲染对象、近背景和远背景。
实验:
baselines:
NeRF:Vanilla NeRF *** 过拟合给定 RGB 图像的场景PixelNeRF ⼀种可推⼴的 NeRF 变体,利⽤局部图像特征进⾏少镜头新颖视图合成MVSNeRF:通过从源图像构建cost-volume获得的局部特征来扩展 NeRF 进⾏少视图合成NeO 360:本文提出的架构将局部和全局特征结合起来,用于通用场景表示学习。


结论:
在本⽂中,本文提出了 NeO 360,这是 NeRF ⽅法的可推⼴扩展,⽤于⽆界360°场景。本文的⽅法依赖于图像条件三平⾯表示来进⾏少量新颖的视图合成。为了为⽆界场景建⽴强⼤的先验,本文提出了⼀个⼤规模数据集 NERDS 360 来研究 360 度设置中的视图合成、重建和分解。本文的⽅法的性能明显优于其他可推⼴的 NeRF 变体,并且在新场景上进⾏测试时实现了更⾼的性能。对于未来的⼯作,本文将探索如何使⽤所提出的⽅法来构建较 少依赖标记数据的先验,例如推理过程中的 3D 边界框,⽽是依赖运动线索在没有标记数据的情况下进⾏有效的场景分解。

原文链接:https://mp.weixin.qq.com/s/rjJlJbbb_oFah2nZoSYQwA
本文由 @小畔畔 于2023-11-06发布在 畔畔网,如有疑问,请联系我们。
上一篇:金爪爪干锅加盟