





NeurIPS 2023 | 「解释一切」图像概念解释器来了,港科大团队出品
- 创业科技
- 2023-11-02
- 10
- 更新:2023-11-02 14:02:34
Segment Anything Model(SAM)首次被应用到了基于增强概念的可解释 AI 上。
你是否好奇当一个黑盒深度神经 *** (DNN) 预测下图的时候,图中哪个部分对于输出预测为「击球手」的帮助更大?

香港科技大学团队最新的 NeurIPS2023 研究成果给出了他们的答案。

论文:https://arxiv.org/abs/2305.10289
项目代码:https://github.com/Jerry00917/samshap
继 Meta 的分割一切 (SAM) 后,港科大团队首次借助 SAM 实现了人类可解读的任意 DNN 模型图像概念解释器:Explain Any Concept (EAC)。
你往往会看到传统的 DNN 图像概念解释器会给出这样的解释 (SuperPixel-Based):

但这类输出通常不能完整地将 DNN 对于输入图像里概念的理解表达给人类。
港科大团队首次将具有强大的概念抓取力的 SAM 和博弈论中夏普利公理 (Shapley Value) 结合起来,构建了端对端具有完整概念的模型解释器,并呈现了非常令人惊叹的结果!!

现在,用户只需要将任意 DNN 接入该解释器的 API,EAC 就可以精准地解释出图中哪些概念影响了模型最终的输出。
算法原理
如下图所示,解释一切 EAC 的算法流程图可大体分为三个阶段:1)SAM 概念抓取,2)利用 Per-Input Equivalence (PIE) 模拟目标 DNN 模型,3)通过计算出 PIE 的夏普利公理值得出近似原目标 DNN 的最终概念解释输出。
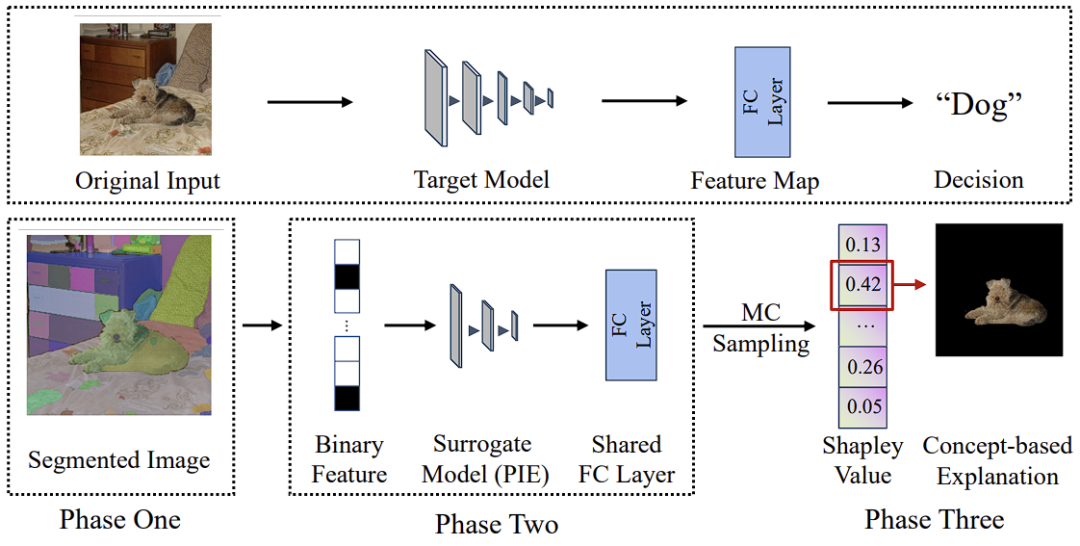
夏普利值实现
在博弈论中,夏普利公理的地位举足轻重。基于它,研究人员可以推算出图片里每一个概念对目标模型输出的贡献值,从而得知哪些概念对于模型预测的帮助更大。不过计算夏普利值所需要的时间复杂度为 O (2^N),这对于几乎任何一个成熟的深度学习模型是灾难性的计算量。
本文为了解决这一问题提出了 Per-Input Equivalence (PIE)轻量型框架。PIE 希望通过一个 surrogate model f' 将原目标 DNN 模型 f 做局部拟合。
PIE 的完整表达式为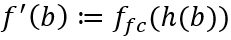 。这里 f_fc 完全保留了原模型的全连接层,h 是一层线性权重用于模拟 f 的特征提取器,输入 b 为一维 one-hot 对一张目标图片里的概念集 C(由 SAM 生成)的编码。算法通过对 PIE 进行蒙特卡洛估算,就可得出 f^' 对于 f 的近似夏普利值。
。这里 f_fc 完全保留了原模型的全连接层,h 是一层线性权重用于模拟 f 的特征提取器,输入 b 为一维 one-hot 对一张目标图片里的概念集 C(由 SAM 生成)的编码。算法通过对 PIE 进行蒙特卡洛估算,就可得出 f^' 对于 f 的近似夏普利值。
文章指出 PIE 的运算十分轻量。在 COCO 标准测试集上,将目标模型设为 ResNet50,平均解释时间仅约为 8.1 秒 / 一张图片。
实验结果
通过给每张测试图逐一添加(Insertion)/ 删除(Deletion)最重要的概念 patch,这两项实验研究者可以直接评估任意解释器在解释目标 DNN 时的表现。
EAC 同时在「添加」和「删除」两项实验中实现了比较优秀的解释效果。
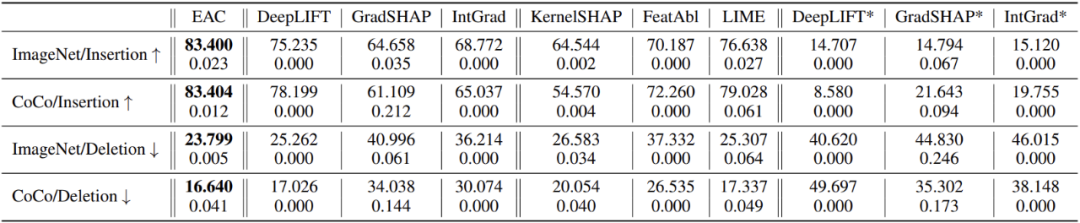
以下是 EAC 效果展示和 baseline 对比:

在文章的最后,团队表示有了 EAC 这项技术,医疗影像,智慧安防等重要的可信机器学习商用应用场景会变的更准确,更可靠。
本文由 @小畔畔 于2023-11-02发布在 畔畔网,如有疑问,请联系我们。