

DSA如何弯道超车NVIDIA GPU?
- 创业科技
- 2023-09-18
- 5
- 更新:2023-09-18 16:02:26
你可能听过以下犀利的观点:
1.跟着NVIDIA的技术路线,可能永远也追不上NVIDIA的脚步。
2.DSA可能有希望能追上NVIDIA,但目前的情况是DSA快死了,看不到任何希望。
另一方面,我们都知道现在大模型正处于风口位置,业界很多人想做大模型芯片,也有很多人想投大模型芯片。
但是,大模型芯片的设计关键在哪,大带宽大内存的重要性好像大家都知道,但做出来的芯片跟NVIDIA相比,又有何不同?
带着问题,本文尝试给大家一点启发。
纯观点的文章会显得比较 *** ,我们就从一个架构的例子来看。
被誉为美国十大独角兽公司之一的SambaNova Systems,在2021年4月,由软银牵头获得了6.78亿美金的D轮投资,成为了一家50亿美金估值的超级独角兽公司。他的前几轮的投资方包括谷歌风投、Intel、Capital、SK、Samsung催化基金等全球最头部的风投基金。那这样一家超级吸金兽到底在做一件什么颠覆性的事情能吸引这么多全球头部投资机构的青睐呢?如果来看他们早期的宣传材料,我们可以看到面对AI巨头NVIDIA,SambaNova走出了一条不一样的路。
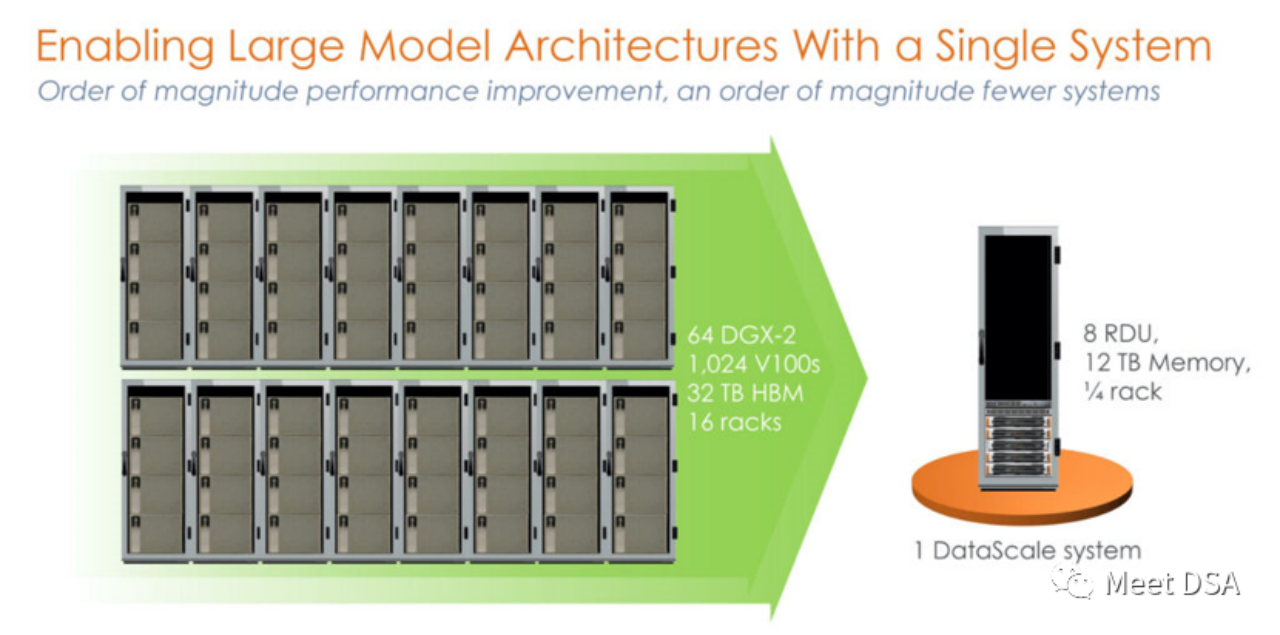
是不是有点震撼?在英伟达平台上用洪荒之力所构建的一个1024的V100集群,居然被SambaNova的一个单机就等价了?!这是之一代的产品,基于SN10 RDU的单机8卡机器。
可能有人会说这个对比显得不太公平,NVIDIA不是有DGX A100吗,可能SambaNova自己也意识到了,二代产品SN30就改成这样了:

DGX A100 是5 petaFLOPS的算力,SambaNova的第二代DataScale的算力也是5 petaFLOPS。Memory对比320GB HBM vs 8TB DDR4(小编猜测可能他文章写错了,应该是3TB * 8)。
第二代芯片实际是SN10 RDU的Die-to-Die版本。SN10 RDU的架构指标:320TFLOPS@BF16,320M SRAM,1.5T DDR4。SN30 RDU就是Double一下,正如以下描述所言:
“This chip had 640 pattern compute units with more than 320 teraflops of compute at BF16 floating point precision and also had 640 pattern memory units with 320 MB of on-chip SRAM and 150 TB/sec of on-chip memory bandwidth. Each SN10 processor was also able to address 1.5 TB of DDR4 auxiliary memory.”“With the Cardinal SN30 RDU, the capacity of the RDU is doubled, and the reason it is doubled is that SambaNova designed its architecture to make use of multi-die packaging from the get-go, and in this case SambaNova is doubling up the capacity of its DataScale machines by cramming two new RDU – what we surmise are two tweaked SN10s with microarchitectures changes to better support large foundation models – into a single complex called the SN30. Each socket in a DataScale system now has twice the compute capacity, twice the local memory capacity, and twice the memory bandwidth of the first generations of machines.”
要点提炼:大带宽,大容量只能二选一,NVIDIA选择了大带宽 HBM,而SambaNova选择了大容量 DDR4。从性能效果看,SambaNova完胜。
如果换成DGX H100,即使是换成FP8这些低精度的技术,也只能缩小差距。
“And even if the DGX-H100 offers 3X the performance at 16-bit floating point calculation than the DGX-A100, it will not close the gap with the SambaNova system. However, with lower precision FP8 data, Nvidia might be able to close the performance gap; it is unclear how much precision will be sacrificed by shifting to lower precision data and processing.”
要是谁能做到这效果,那不是妥妥的大模型芯片解决方案吗,而且可以直面NVIDIA的竞争啊!
(可能你会说Grace CPU也可以接LPDDR,利于增大容量之类的,反观SambaNova是怎么看这个事情:Grace不过是一个大号的内存控制器,但也只能给Hopper带来512GB的DRAM,而一个SN30就有3TB的DRAM。
“We have joked about the ‘Grace’ Arm CPU from Nvidia being a glorified memory controller for the Hopper GPU. In a lot of cases, that is what it really will be – and only with a maximum of 512 GB per Hopper GPU in a Grace-Hopper superchip package. That is still a lot less memory than SambaNova is supplying per socket, at 3 TB.”)
历史告诉我们,再如日中天的帝国,可能也要当心那道不起眼的裂缝!
前段时间,华为大神夏core从成本的角度去推断,NVIDIA帝国的破绽可能在$/GB(DRAM的成本)上,疯狂堆料廉价DDR做大片内I/O,可以革命NVIDIA;
(引申:https://zhuanlan.zhihu.com/p/639181571)
而另外一个研究DSA的知乎大神mackler给出了他的观点,从$/GBps(数据搬移)的角度看,HBM性价比更高,因为LLM虽然对内存容量有比较大的需求,但对于内存带宽也有巨大的需求,训练需要大量的参数需要在DRAM来交换。
(引申:https://zhuanlan.zhihu.com/p/640901476)
从SambaNova的架构例子来看,大容量廉价DDR是可以解决LLM的问题的,这印证了夏core的判断!但是mackler观点中对数据搬移的巨大带宽的需求也是问题所在,那SambaNova是如何解决的?
这就需要进一步理解RDU架构的特点了,其实也很好理解:
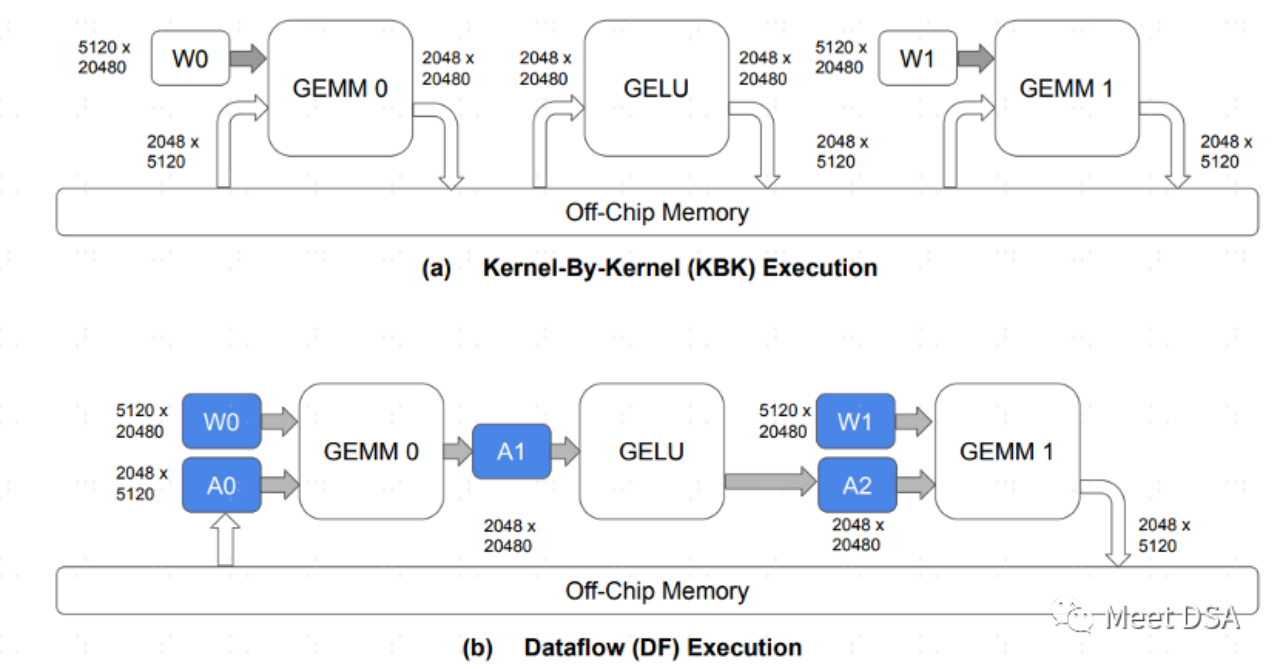
A是传统的GPU架构数据交换的范式,每个算子都需要去片外DRAM交换数据,这种来回的交换占据大量的DDR带宽应该比较好理解。B是SambaNova的架构可以做到的,模型计算过程,把很大部分的数据搬移都留在片内,不需要来回的去DRAM进行交换。
因此,如果能做到B这样的效果,大带宽,大容量二选一的问题,就可以安全的选大容量。这正如以下这段话所言:
“The question we have is this: What is more important in a hybrid memory architecture supporting foundation models, memory capacity or memory bandwidth? You can’t have both based on a single memory technology in any architecture, and even when you have a mix of fast and skinny and slow and fat memories, where Nvidia and SambaNova draw the lines are different.”
面对强大的NVIDIA,也不是没有希望!但跟随NVIDIA做GPGPU这种策略就不好说了。看起来大模型芯片正确的思路在这里:堆料便宜的DRAM,同等算力规格,性能可以做到NVIDIA的6倍以上!
那么,SambaNova的RDU/DataFlow架构具体是怎么做到B的效果,或者有没有其他办法可以做到类似B的效果呢?我们下回再跟大家分享,感兴趣的伙伴欢迎长期关注我们的更新。
引申阅读参考:
[1]https://sambanova.ai/blog/a-new-state-of-the-art-in-nlp-beyond-gpus/
[2]https://www.nextplatform.com/2022/09/17/sambanova-doubles-up-chips-to-chase-ai-foundation-models/
[3]https://hc33.hotchips.org/assets/program/conference/day2/SambaNova%20HotChips%202021%20Aug%2023%20v1.pdf
[4]《TRAINING LARGE LANGUAGE MODELS EFFICIENT *** WITH SPARSITY AND DATAFLOW》
[5]https://zhuanlan.zhihu.com/p/639181571
[6]https://zhuanlan.zhihu.com/p/640901476
本文由 @小畔畔 于2023-09-18发布在 畔畔网,如有疑问,请联系我们。